HiPERiSM - High Performance Algorism Consulting
HCTR-2001-3: Compiler Performance 4


1.0 The Stommel Ocean Model: 1-D MPI decomposition
1.1 Serial and MPI code
This is a comparison of parallel MPI performance with SUN Fortran compilers on the SUN E10000™ platform for a floating-point intensive application. The application is the Stommel Ocean Model (SOM77) and the Fortran 77 source code was developed by Jay Jayakumar (serial version) and Luke Lonnergan (MPI version) at the NAVO site, Stennis Space Center, MS. It is available at http://www.navo.hpc.mil/pet/Video/Courses/MPI_Finite. The algorithm is identical to the Fortran 90 version discussed in report HCTR-2001-2 but the Fortran 77 version allows for more flexibility in the domain decomposition for MPI. The serial version (STML77S0) and MPI parallel version (STMLPI1D) of SOM77 have the calling tree (produced by Flint™ from Cleanscape Software) as shown in Table 1.1.
| Table 1.1: Call trees for SOM77 in serial and MPI 1-D parallel versions | |
Serial |
1-D parallel |
STML77S0-+-(MPI_INIT) +-(MPI_WTIME) +-GRID +-FORCING +-INITIAL +-COEFF +-BCS +-JACOBI +-RESIDUAL +-COPYSOL +-(MPI_FINALIZE) |
STMLPI1D-+-(MPI_INIT) +-(MPI_COMM_SIZE) +-(MPI_COMM_RANK) +-(MPI_WTIME) +-(MPI_BCAST) +-GRID +-FORCING +-INITIAL +-COEFF +-BCS +-NEIGHBORS +-EXCHANGE-+-(MPI_SEND) | +-(MPI_RECV) +-JACOBI +-RESIDUAL--(MPI_ALLREDUCE) +-COPYSOL +-(MPI_FINALIZE) |
This
is a 1-dimensional domain decomposition in the y direction with horizontal slabs of the
domain passed to different MPI processes (one slab per process). In the MPI version all
parameters must be broadcast by process with rank 0 to all processes before computation
begins. Otherwise the code is identical to the serial version excepting that each MPI
process operates on its own slab of the domain. At the beginning of each iteration the
slabs synchronize values by exchanging adjacent ghost rows (parallel to the x direction)
with the nearest neighbor processes whenever slabs are adjacent (subroutine EXCHANGE). The
top row of the uppermost slab and the lowest row of the bottommost slab do not exchange
rows since they correspond to domain boundaries.
The compute kernel of the SOM77 is a double-nested loop that performs a Jacobi iteration sweep over a two-dimensional finite difference grid and the number of iterations is set to 100. More details of the model are discussed in HiPERiSM courses HC6 and HC8 (see the services page). For this study the problem size sets the number of interior grid point at N=1000 for a Cartesian grid of 1000 x 1000.
2.1 MPI parallel performance
This section shows MPI parallel performance for the Stommel Ocean Model (SOM77) in a 1-D MPI domain decomposition with the SUN Fortran 77 compiler. Figure 2.1 shows the time in seconds (as reported by the MPI W_TIME procedure) and Figure 2.2 shows the corresponding speed up. Table 2.1 summarizes efficiency values and shows a clear cache effect in the superlinear speed up.
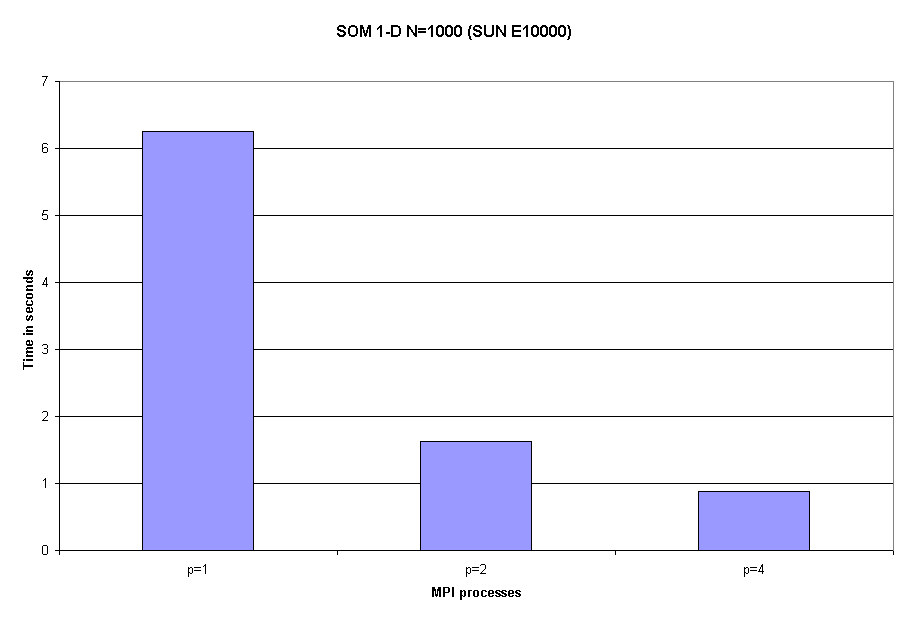
Fig. 2.1. Time to solution in seconds for SOM 1-D when N=1000 on the SUN E10000 for 1, 2 and 4 MPI processes.
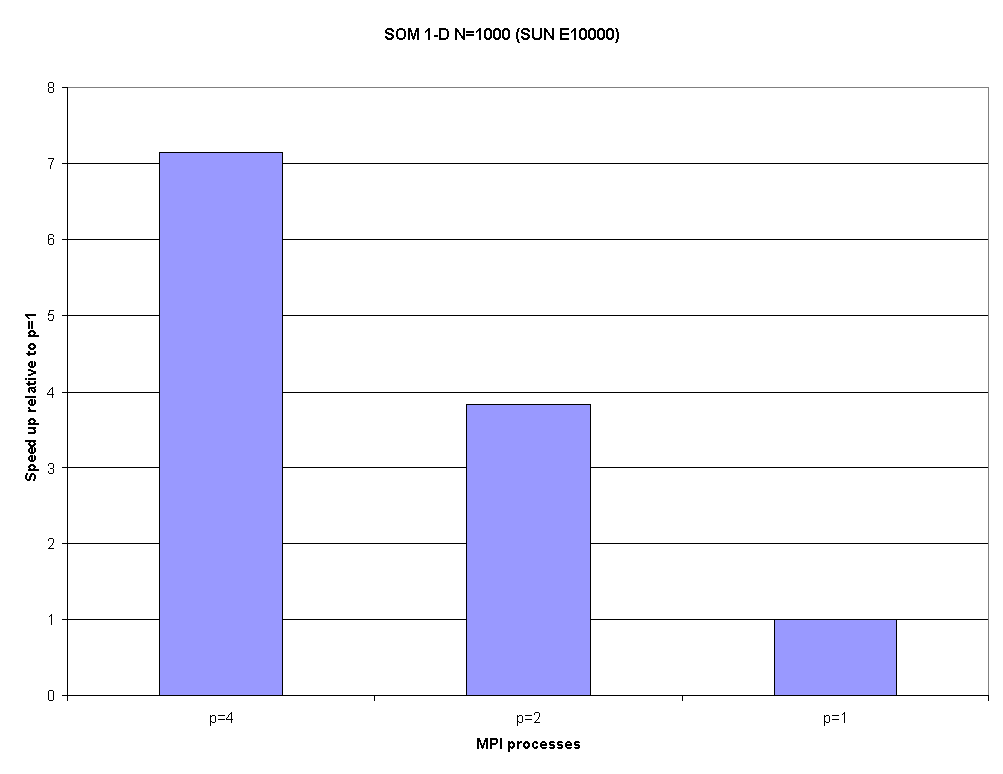
Fig. 2.2. Speed up for SOM 1-D when N=1000 on the SUN E10000 for 4, 2 and 1 MPI processes.
| Table 2.1: Performance results for SOM77 in an MPI 1-D parallel version | |||
P |
Time |
Speed up |
Efficiency |
1 |
6.25 |
1.00 |
1.00 |
2 |
1.63 |
3.83 |
1.92 |
4 |
0.88 |
7.14 |
1.79 |
![]()
![]()
HiPERiSM Consulting, LLC, (919) 484-9803 (Voice)
(919) 806-2813 (Facsimile)