HiPERiSM - High Performance Algorism Consulting
HCTR-2004-6: Compiler Performance 13
COMPARING COMPILERS ON INTEL™ PENTIUM 3 and PENTIUM 4 PROCESSORS WITH MM5 FOR THE STORM OF THE CENTURY BENCHMARK
George Delic
HiPERiSM Consulting, LLC.
1. INTRODUCTION
This is part of a series of reports on a project to evaluate industry standard fortran 90/95 compilers for IA-32 Linux™ commodity platforms. This report shows results, in a side-by-side comparison for each compiler, for the Intel™ Pentium 3 (P3) and Pentium 4 Xeon (P4) processors for the MM5 Community Model with the Storm-of-the-Century (SOC) benchmark.
2.0 CHOICE OF HARDWARE AND OPERATING SYSTEM
Results for the wall clock time are compared for benchmarks compiled using two different Fortran compilers with the Linux™ operating system. For this project benchmarks were executed in serial mode on a dual processor Intel™ Pentium III (256KB L2 cache) and a dual processor Pentium 4 Xeon 3.06GHz (1MB L3 cache). These architectures offer Streaming Single-Instruction-Multiple-Data Extensions (with version 2, SSE2, for the P4 Xeon). This enables vectorization of loops operating on multiple elements in a data set with a single operation.
3.0 CHOICE OF COMPILERS
The choice of compilers for Linux™ IA-32 platforms now includes several vendor-supported products. The importance of this category is that vendor products have technical support and undergo continuous development with ports to new architectures as they arrive in the marketplace. The two compilers chosen in this survey are described separately in the following sections and compiler switches used in the benchmarks are also discussed.
3.1 Intel
The Intel Fortran Compiler version 8.0 (Linux™ distribution) targets both Intel IA-32 and IA-64 (Itanium) architectures, but only the former has been used in this project so far. Details on the compiler features are available at HiPERiSM Consulting, LLC’s URL. Code for the P4 target architecture is generated with the –tpp7 switch and SSE2 instructions with the –xW switch. It is worthwhile noting that loop vectorization appears to be implemented only when this last switch is enabled (for single precision arithmetic as used here). The compiler build used was 8.0.046.
3.2 Portland
The pgf90™ fortran compiler (Linux™ distribution) from the Portland Group, (http://www.pgroup.com) was used in the CDK 4.0 (for P3) and CDK 5.1-3 (for P4) releases. This compiler supports OpenMP, MPI and OpenMP+MPI parallel applications on HiPERiSM’s IA-32 Linux™ clusters. The –fast compiler switch enables automatic architecture detection for either the P3 or P4. Note that both releases offer additional performance enhancement with switches for the Pentium 3/4 processors to use the SSE/SSE2 instruction sets. Vector instructions are enabled with the –Mvect switch without requiring the use of SSE/SSE2 instructions, which, however, may be enabled with –Mvect=sse (4.0 and 5.1), or –fastsse (5.1, only). The compiler build used was 5.1-3.
4.0 CHOICE OF BENCHMARKS
4.1 Introduction
The MM5 Community Model has been executed on a wide variety of platforms and the serial version is used here in studying how a compiler and architecture interact for a real-world model that was optimized for performance on vector register machines. A fuller discussion (and download) of MM5 (version 3) is available at http://www.mmm.ucar.edu/mm5/mm5-home.html. What follows introduces only the essentials of the case studied here.
4.2 The MM5 Community Model
The MM5 code is a legacy Fortran 77 code and for this report the following steps were followed in download, compilation and execution using the files found at the MM5 URL give in the previous section.
1. Download of MM5.TAR.gz.
2. gunzip and untar of this file (creates a directory MM5).
3. Download of input2mm5.tar.gz and soc_benchmark_config.tar.gz files from the TESTDATA directory.
4. gunzip and untar of both the files from step 3 in the MM5/Run directory.
5. cd to the MM5 directory.
6. cp configure.user.linux configure.user.
7. Edit the configure.user file and set FC (compiler), FCFLAGS (switches) and LDOPTIONS (loader options).
8. make &> make.log
9. cd Run
10. /usr/bin/time ./mm5.exe &> mm5.print.out.
Step 8, if successful, produces an mm5.exe file in the Run directory and the output file in Step 10 has timing results appended. This report discusses only execution times while issues of numerical differences are the subject of a separate report.
5.0 COMPARING EXECUTION TIMES
The following sections summarize execution time with two compilers for the MM5 Version 3 for the Storm-of-the-Century (SOC) benchmark as described in Section 4.2.
5.1 Timing performance
Whole code execution was measured with the time command as described in Step 10 of Section 4.2 and total elapsed time is reported.
5.2 MM5 SOC results
For MM5 the choice of compiler switches is summarized in Table 5.1 for the Portland compiler and in Table 5.2 for the Intel compiler. Note the use of the target architecture switches (often these are implicit in the optimization level). Timing results are shown in Tables 5.3 while Figures 1 and 2 show these times as bar charts.
|
Table 5.1 Portland compiler command and switches for the MM5 SOC benchmark on the P3 (pgf90 4.0 and #=6) and P4 Xeon (pgf90 5.1 and #=7) processors. |
|
|
Compiler and version |
Compiler command and selected switches |
|
pgf90 (noopt) |
-O0 –tp p# -Mcray=pointer –pc 32 –Mnoframe -Mbyteswapio |
|
pgf90 (opt) |
-O2 –tp p# -Mcray=pointer –pc 32 –Mnoframe -Mbyteswapio |
|
pgf90 (vector) |
-fast -Mvect -Mcray=pointer –pc 32 -Mbyteswapio |
|
pgf90 4.0 (SSE) pgf90 5.1 (SSE) |
-fast –Mvect=sse -Mcray=pointer –pc 32 –Mbyteswapio -fastsse -Mcray=pointer –pc 32 -Mbyteswapio |
|
Table 5.2 Intel compiler command and switches for the MM5 SOC benchmark on the P4 Xeon processor. |
|
|
Compiler and version |
Compiler command and selected switches |
|
ifort 8.0 (noopt) |
-fpp -O0 –Ob0 –unroll0 –FI –tpp7 -safe_cray_ptr –pc32 –convert big_endian |
|
ifort 8.0 (opt) |
-fpp –O2 –FI –tpp7 -safe_cray_ptr –pc32 –convert big_endian |
|
ifort 8.0 (SSE) |
-fpp –xW –O2 –FI –tpp7 -safe_cray_ptr –pc32 –convert big_endian |
|
Table 5.3 Elapsed time (seconds) for the choice of compilers and switches in Tables 5.1 and 5.2. |
||||
|
Case |
noopt |
opt |
vector |
SSE |
|
P3 pgf90 |
2147.2 |
1664.5 |
1739.3 |
1598.3 |
|
P4 pgf90 |
894.6 |
610.5 |
623.6 |
552.2 |
|
P4 ifort |
1068.2 |
485.5 |
---------- |
365.5 |
Some observations on the grouping of these compiler switches are in order. As a base-line the noopt group disables all optimization for either compiler. The opt group enables some optimization, however, the optimizations applied are different for the two compilers so the equivalence is not precise. The equivalence in the vector group does not exist because the pgf90 compiler allows separation of vector and SSE instruction implementation, whereas the Intel compiler does not (and therefore the Intel entry is left blank in Table 5.3 and Figure 2). The Intel compiler allows vectorization of loop constructs only when the –xW construct is enabled and this also enables SSE instruction use. Note that for the SSE group with the Portland compiler, SSE instructions are enabled either by using –Mvect=sse, or, what is new in version 5.1, –fastsse (for differences in this choice see the documentation). The latter choice produced an additional 21 seconds speed up for a result of 552.2 seconds elapsed time (as shown in Table 5.3). As a final note, the MM5 download described in Section 4.2, has FC set as the Portland compiler with the FCFLAGS set as shown in the opt group in Table 5.1.
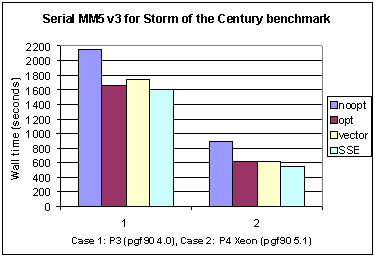
Fig. 1 Elapsed time for MM5 with the SOC benchmark for the Portland pgf90 compiler using version 4.0 (P3, Case 1), and 5.1-3 (P4, Case 2).
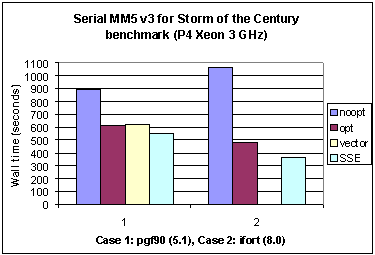
Fig. 2 Elapsed time for MM5 with the SOC benchmark for the Portland 5.1 (Case 1), and Intel 8.0 (Case 2) compilers.
It is interesting to observe the changes in performance shown in Figure 1 between the Pentium 3 and 4. As expected the execution time decreases for P4 relative to the P3 and on both platforms there is a clear improvement in performance when the opt group of switches is used with –O2. Higher level optimizations are available with both compilers, e.g. Inter Procedural Analysis (IPA), but some strange things begin to happen and it was decided not to pursue IPA options with the large and complex MM5 code at this time. Table 5.3 and Figure 1 show that the –Mvect choice on either processor does not improve performance. The Portland compiler reported the lowest wall clock times for the SSE group of compiler switches. There is a gain with SSE enabled of 3.9% and 9.5%, for P3 and P4, respectively. On the Pentium 4 the situation differs in two respects: (a) version 5.1-3 has been used, and (b) the new –fastsse switch was used. The latter choice delivered a 21 second improvement.
To compare the relative performance for each compiler on the same architecture, Figure 2 shows the Pentium 4 elapsed times. As noted above there is no exact equivalence between the two compilers for the vect group of switches. But the other three groups should be closely comparable. For the baseline, with the noopt choice, the Intel compiler lags pgf90, but the situation is reversed for the opt group of switches where the Intel compiler delivers a 20.5% smaller elapsed time. However, the largest difference between the two compilers is for the SSE group of switches, where the Intel compiler delivers a 33.8% smaller elapsed time.
6.0 EVALUATION OF RESULTS
For the two compilers evaluated here Table 6.1 shows some direct ratios of elapsed times. The columns show, respectively, the selected group of compiler switches, the ratio of P3 to P4 times for the Portland compiler, and the ratio of Portland to Intel compiler elapsed times on the P4 Xeon processor. Overall, the performance gain between 2.4 and 2.9 for P4 versus the P3 (shown in the second column) is disappointing. Considering the three-fold increase in clock speed and the addition of a 1MB L3 cache more could have been expected. The situation can of course change as problem size changes, however these results are a clear indication of the penalties that come with commodity architectures. It is surmised that this result is due to increases in cache misses and memory latency. This result is surprising in view of the sophisticated compiler optimizations employed by all these compilers. Presumably the additional layer of L3 cache on the P4 Xeon requires careful hand-tuning. A deeper performance analysis of the underlying reasons for this behavior is the subject of a future report. Memory bandwidth issues on both the P3 and P4 nodes are the subject of a separate report in this series.
|
Table 6.1 Comparison of execution times for the MM5 and the SOC benchmark with two compilers on Pentium 3 and 4 processors. |
||
|
|
pgf90 P3 time / P4 time |
pgf90 P4 time / ifort P4 time |
|
noopt |
2.4 |
0.84 |
|
opt |
2.7 |
1.26 |
|
vector |
2.8 |
--- |
|
SSE |
2.9 |
1.51 |
On the P4 Xeon processor it is clear from Figure 2 (and Table 6.1) that the Intel compiler delivers the best performance once SSE is enabled. A deeper study of the causes for this performance gain with the newer hardware and compiler technology seems in order and is deferred for a future report.
7.0 CONCLUSIONS
This report presented performance results of two fortran compilers in the IA-32 environment. The performance differences found were specific to the MM5 Storm-of-the-Century benchmark performed in single precision. Nevertheless, as an example of a “real-world code” MM5 with the SOC benchmark reveals that performance gains are different with different compilers. In particular, when the SSE instruction set is enabled on the P4 Xeon architecture, there is a sharp differentiation in performance gain between the two compilers evaluated here. The full potential of serial code optimizations with these compilers have not been tested in this report because the MM5 community seems to value consequences for numerical results and prefers a conservative approach. Sophisticated compiler optimizations apply idiom recognition and source code transformations that can (and often do) result in numerical differences. However, some optimization work by the end user of cache-based architectures will always remain even when code with good vector structure is presented to compilers with powerful optimization strategies such as the ones tested here.
The analysis in subsequent reports will include in-depth evaluation of performance of these compilers with specialized software such as the Intel VTune™ Performance Analyzer. Also in this evaluation the consequences of compiler switches for numerical precision and stability will be investigated.
![]()
![]()
HiPERiSM Consulting, LLC, (919) 484-9803 (Voice)
(919) 806-2813 (Facsimile)

