HiPERiSM - High Performance Algorism Consulting
HCTR-2010-1: CMAQ Performance 1
CMAQ FOR MANY-CORE AND GPGPU PROCESSORS
George Delic
HiPERiSM Consulting, LLC.
1.0 INTRODUCTION
This is the first of a new series of reports describing CMAQ ports to multi-core and many-core processors. It presents a description of the platforms, compilers, data, and CMAQ versions used in the subsequent series of reports (HCTR-2010-2 to HCTR-2010-5). This series of reports include results reported in conference presentations at the Annual CMAS meetings (http://www.cmascenter.org), but may also include some further detail that was omitted for space reasons. Previous presentations by HiPERiSM Consulting, LLC, in this conference series have reported performance results for both serial and multithread parallel versions of CMAQ (Delic, 2003-2009). These reports presents results of porting the multithreaded version of CMAQ to recent multi-core and many-core processors. Examples of the former are traditional x86_64 processors while examples of the latter are General Purpose Graphical Processing Units (GPGPU). Substantial portions of the work described here was performed under contract to the U.S. EPA (See the Acknowledgements for details).
Both Rosenbrock (ROS3) and Gear (GEAR) chemistry solver versions of CMAQ offer potential for thread parallel code development, whereas the Euler-Backward (EBI) solver does not. Recently a thread-parallel version of the CMAQ Rosenbrock solver (hereafter ROS3-HC), developed by HiPERiSM Consulting, LLC, (Delic, 2009, annual CMAS meeting), was delivered under contract to the U.S. EPA. Selected results from this study are presented here (HCTR-2010-2 to HCTR-2010-4), together with an exploration of GPGPU architectures (HCTR-2010-5). A case study uses the thread-safe version of the CMAQ Rosenbrock solver. Although some results for CMAQ 4.7 are included, this report will focus on experiences with CMAQ 4.6.1 for ease of comparison with the previous work.
The ROS3-HC code is a hybrid parallel model with three levels of parallelism. The (outer) Message Passing Interface (MPI) level is the one previously delivered in the standard U.S. EPA distribution. The new (inner) parallel layers developed at HiPERiSM have added both thread-level parallelism and instruction-level parallelism (at the vector loop level). These new parallel layers in CMAQ are suitable candidates for both multi-core and many-core targets.
2.0 CHOICE OF PLATFORMS
2.1 Hardware
The hardware systems chosen were the platforms at HiPERiSM Consulting, LLC, shown in Table 2.1. The GPGPU device shown in Table 2.1 was the first release with native double precision capability and 4 Gigabytes of memory. It is currently installed on the quad-core 1 (QC-1) platform at HiPERiSM. The quad-core 2 (QC-2) platform has scope for the addition of two (more recent) GPGPU devices that offer 448 cores and up to 6 Gigabytes of memory. Each of the two platforms, QC-1 and QC-2, have a total of 8 cores and, when combined form a heterogeneous cluster. This cluster is used for either MPI only, or hybrid thread-parallel plus MPI execution, and results for both modes are reported below.
Table 2.1. Platforms at HiPERiSM Consulting, LLC
|
Platform |
SGI Altix |
quad-core 1 |
quad-core 2 |
GPGPU |
|
Processor |
Intel™ IA64 (107W) |
Intel™ IA32 (X5450) |
Intel™ IA32 (W5590) |
Nvidia™ (C1060) |
|
Cores per processor |
1 core |
4 cores |
4 cores |
240 cores |
|
Clock |
1.5GHz |
3.0GHz |
3.33GHz |
1.3GHz |
|
Band-width |
6.4 GB/sec |
10.6 GB/sec |
64.0 GB/sec(1) |
102 GB/sec |
|
Bus speed |
400 MHz |
1333 MHz |
1333 MHz(2) |
800 MHz(4) |
|
L1 cache |
32KB |
64 KB |
64 KB |
NA |
|
L2 cache |
1 MB |
12MB(3) |
256MB |
NA |
|
L3 cache |
4MB |
NA |
8MB |
NA |
|
(1) Theoretical maximum. (2) Value for one DDR3 DIMM per each of three channels per CPU (This value drops with more DIMMs per channel). (3) Intel's first generation of Quadcore CPUs shared L2 cache between cores. (4) This is the on-device memory speed. Communication between the GPGPU device and the host is via a PCI Express 2.0 x 16 system interface. |
||||
2.2 Hardware bandwidth for MPI
Fig. 2.1 shows a comparison of MPI bandwidth measurements for the SGI Altix and the quad-core cluster (dual 4 core CPUs on two nodes) with NumaLink® and Infiniband®SDR interconnect fabrics, respectively. The SGI Altix is limited to 8 single core CPUs, and the quad core cluster has two nodes with 2 quad core CPUs each. The “local” curve of the quad-core cluster result corresponds to scheduling MPI processes on the same (master) node. However, the “non-local” results correspond to MPI processes distributed between the two nodes in the quad-core cluster (with the exception of two MPI processes when both processes resided on the master node). The remarkable feature of Fig. 2.1 is how the on-node bandwidth tracks closely the NumaLink® results for the SGI Altix. This reflects the bandwidth boost of the quad-core architecture over previous IA32 CPU generations. Clearly, it is most beneficial for parallel execution on current multi-core cluster nodes to remain on-node as much as possible to utilize the on-node bandwidth.
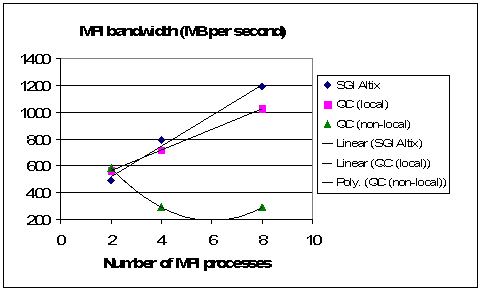
Fig 2.1: MPI bandwidth at HiPERiSM Consulting, LLC.
2.3 Compilers
Two popular compilers were used for this CMAQ study. A comparison was made for both the Intel™ 11.x and Portland 10.x Fortran compilers on 64-bit SUSE Linux operating systems. The ROS3-HC multi-threaded parallel version was compiled and executed with both compilers on all platforms shown in Table 2.1. However, while the Intel™ compiler may be implemented with the CUDA™ GPGPU programming environment (CUDA), this was deemed too labor intensive when compared with the GPGPU interface of the PGI Accelerator™ Fortran compiler (PGI). This feature-rich compiler simplifies prototype development and testing.
For each compiler four groups of optimization switches were selected corresponding to no optimization (ifc1, pgf1), some optimization (ifc2, pgf2), best optimization (ifc4, pgf4), and enabling control of arithmetic precision (ifc3, pgf3). The last choice increases execution time but constrains arithmetic operations to improve numerical precision by several orders of magnitude with either compiler. The reason for such constraints is that some CMAQ species are more sensitive to numerical differences than others, largely based on the variability in concentration magnitudes (those with largest variation being more at risk). This study found that although the highest optimization level, ifc4 of the Intel™ compiler produce the shortest runtime, in some cases it also introduces numerical differences that compromise numerical precision for a small (10%) subset of the species concentration value population. This observation concerning the Intel™ compiler applies for both Itanium2™ and current generation quad-core processors.
3.0 EPISODES STUDIED
For CMAQ 4.6.1 results the model episode selected was for August 14, 2006 (hereafter 20060814). This used the CB05 mechanism with Chlorine extensions and the Aero 4 version for PM modeling. For CMAQ 4.7.1 the model used the episode for August 09, 2006 (hereafter 20060809) with data provided by the U.S. EPA. Both episodes were run for a full 24 hour scenario on a 279 X 240 Eastern US domain at 12 Km grid spacing and 34 vertical layers.
ACKNOWLEDGEMENTS
Part of this work was performed by HiPERiSM Consulting, LLC, as subcontractor to Computer Sciences Corporation, under U.S. EPA SES3 Contract GS-35F-4381G BPA 0775, Task Order 1522
Follow the "Next" button to view the next report in this series.
![]()
![]()
HiPERiSM Consulting, LLC, (919) 484-9803 (Voice)
(919) 806-2813 (Facsimile)

