HiPERiSM - High Performance Algorism Consulting
HCTR-2011-1: Bandwidth Benchmarks For Intel® and AMD® processors
BANDWITH BENCHMARKS FOR Intel and AMD PROCESSORS
George Delic
HiPERiSM Consulting, LLC.
1.0 BANDWIDTH BENCHMARK
1.1 The b_eff code
HiPERiSM has used the b_eff bandwidth benchmark over many years. The source code and its description is available at https://fs.hlrs.de/projects/par/mpi/b_eff/. The same site lists many measurements across various HPC platforms and is useful as a stable metric for use with old and new architectures. It main purpose is to test interconnects on clusters, but here it is used to compare the developments in on-node bandwidth for several nodes at HiPERiSM.
1.2 Hardware test beds
The hardware platforms for this bandwidth testing exercise are those installed at HiPERiSM as listed in Table 1.1. Of interest here is to compare some of the latest multi-core nodes with the legacy NumaLink® interconnect of the SGI Altix® and with each other in view of the claims of peak theoretical bandwidth in the newer CPU technology from Intel and Advanced Micro Devices (AMD). The Itanium platform is a four node cluster with two single core CPUs per node, whereas all other nodes are CPUs on a single mother board sharing a bus architecture.
Table 1.1. Configuration and specification information for the Intel Itanium2®, first/second generation quad-core processor, and AMD 12-core processor platforms.
|
Node name |
node100 |
node17 |
node18 |
node19 |
|
Platform |
Itanium |
quad-core 1 |
quad-core 2 |
12 core |
|
Operating system |
SuSE Linux 10.17 |
SuSE Linux 11.1 |
SuSE Linux 11.1 |
SuSE Linux 11.3 |
|
Processor |
Intel™ IA64 (107W) |
Intel™ IA32 (X5450) |
Intel™ IA32 (W5590) |
AMD™ (6176SE) |
|
Processor count |
8 |
2 |
2 |
4 |
|
Cores per processor |
1 |
4 |
4 |
12 |
|
Core count |
8 |
8 |
8 |
48 |
|
Clock |
1.5GHz |
3.0GHz |
3.33GHz |
2.3GHz |
|
Bandwidth(1) |
6.4GB/sec |
10.6GB/sec |
64.0 GB/sec |
42.7 GB/sec |
|
Bus speed |
400 MHz |
1333 MHz |
1333 MHz(2) |
1333 MHz |
|
L1 cache |
32KB |
64 KB |
64 KB |
64 KB |
|
L2 cache(3) |
1 MB |
12MB(4) |
256MB |
512K(5) |
|
L3 cache(6) |
4MB |
NA |
8MB |
12MB |
|
(1) Theoretical maximum per CPU. (2) Value for one DDR3 DIMM per each of three channels per processor (This value drops with more DIMMs per channel). (3) For each of Data and Instruction cache. (4) Intel's first generation of Quadcore CPUs shared L2 cache between cores. (5) Per core. (6) Per socket |
||||
2.0 COMPILING THE BENCHMARK
To compile the b_eff.c code, the Portland PGCC compiler was used on the x86_64 nodes and the gcc compiler was used on the Itanium® platform. Various values of the MEMORY_PER_PROCESSOR parameter were tried, but most results reported here were for a value of 3072 MBytes. The number of processors varied up to the maximum core count for the respective nodes. The mpirun command was run with the -all-local switch to contain executions on-node.
3.0 RESULTS OF BENCHMARKS
3.1 Four platforms up to 8 cores each
Preliminary results for up to 8 MPI processes using each of four nodes are summarized in Table 3.1 and Fig. 3.1. The vendor CPU numbers are as shown for the corresponding nodes in Table 1.1.
Table 3.1. Bandwidth in MBytes per second for four separate cluster nodes for the number of processors and cores listed in Table 1.1.
|
Number of MPI processes |
Intel Itanium2 |
Intel X5450 |
Intel W5590 |
AMD 6176SE |
| 2 | 489 | 564 | 1038 | 513 |
| 4 | 791 | 715 | 1211 | 898 |
| 6 | 877 | 1688 | 1103 | |
| 8 | 1191 | 1027 | 2165 | 1380 |
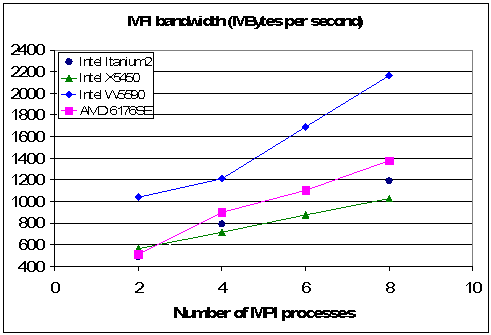
Fig 3.1: Effective bandwidth scaling with MPI process count with four separate cluster nodes for the number of processors and cores listed in Table 1.1.
It is notable that while the first generation Intel Quad core CPU (X5450) closely tracks the Itanium2 results with increasing MPI process count, the measured bandwidth of the second generation Intel Nehalem CPU (W5590) approximately doubles the effective bandwidth in this range. The AMD 12-core CPU (6176SE) falls between the two Intel processor results. In all cases the bandwidth rises with MPI process count, but is steepest for the Intel Nehalem platform between 4 and 8 MPI processes.
3.2 AMD versus Intel platforms
Table 3.2 and Fig. 3.2 compare the Intel Nehalem quad core and the AMD 12 core nodes. Although the Intel Nehalem has impressive bandwidth scaling this is matched by the AMD platform with a little less than double the number of processes.
Table 3.2. Bandwidth in MBytes per second for Intel Nehalem quad core and AMD 12 core platform nodes.
| Process count | 2 | 4 | 6 | 8 | 10 | 12 | 14 | 16 | 24 | 32 | 40 | 48 |
| Intel W5590 | 1038 | 1211 | 1688 | 2165 | ||||||||
| AMD 6176SE | 513 | 898 | 1103 | 1380 | 1595 | 1890 | 2170 | 2386 | 3409 | 4139 | 4579 | 4919 |
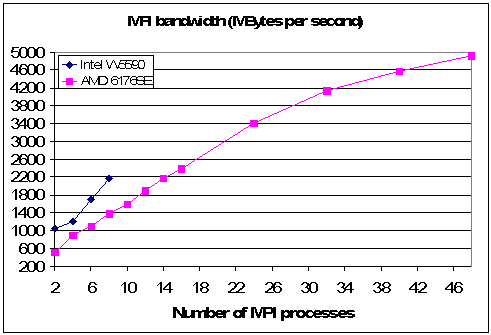
Fig 3.2: Effective bandwidth scaling with MPI process count on quad core Intel and 12 core AMD cluster nodes listed in Table 1.1.
The notable features are that above 4 MPI processes (a) the Nehalem platform shows a distinct increase in slope and (b) the AMD platform shows linear scaling up to half the total core count (24), followed by a gentle bending over above this point.
3.3 Ping-pong Latency for AMD versus Intel platforms
The b_eff benchmark also reports the ping-pong latency and selected values are reported here for the quad core Intel Nehalem and 12 core AMD platforms listed in Table 1.1. Fig. 3.3 shows results up to 12 MPI processes. In both cases latency climbs significantly above 4 MPI processes and this result is probably due to dependency on which cores and CPUs are occupied by them. The other notable feature is the lower latency for the AMD platform for 6 or fewer MPI processes. However, since most real-world applications would use more than 4 MPI processes the differences between the two CPU types will depend on the nature of the application.
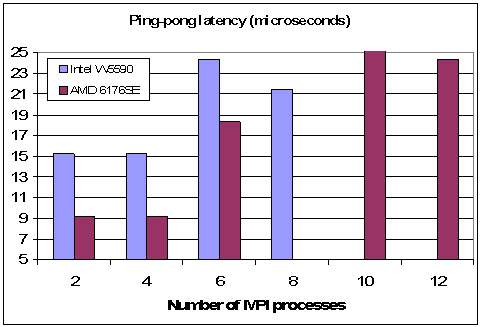
Fig 3.3: Ping-pong latency in microseconds on quad core Intel and 12 core AMD cluster nodes listed in Table 1.1.
6.0 CONCLUSIONS
Exploratory benchmark measurements confirm the impressive effective bandwidth and latency results that are now available for commodity cluster nodes. Not so long ago such performance was only possible on selected proprietary HPC architectures. Now it appears that exceptional performance is available in commodity environments. Actual performance of these commodity solutions in real-world applications will vary and results for specific bench marks and Air Quality Models (AQM) are the subject of subsequent reports.
![]()
![]()
HiPERiSM Consulting, LLC, (919) 484-9803 (Voice)
(919) 806-2813 (Facsimile)

