HiPERiSM - High Performance Algorism Consulting
HCTR-2004-4: Compiler Performance 11
COMPARING COMPILERS ON INTEL™ PENTIUM 3 and PENTIUM 4 PROCESSORS WITH THE SERIAL STREAM BENCHMARK
George Delic
HiPERiSM Consulting, LLC.
1. INTRODUCTION
This is part of a series of reports on a project to evaluate industry standard fortran 90/95 compilers for IA-32 Linux™ commodity platforms. This report shows results, in a side-by-side comparison for each compiler, for the Intel™ Pentium 3 (P3) and Pentium 4 Xeon (P4) processors for the serial STREAM benchmark. The purpose of this benchmark in this application is to measure memory bandwidth on these commodity platforms. In this report the results of the serial version of the STREAM benchmark are reported and the next report in this series reports on the (tuned) parallel OpenMP version.
It has been known for some time that multiprocessor commodity hardware encounters memory bandwidth bottle-necks when more than one processor is active. This limitation affects both OpenMP and MPI parallel applications. As an example of the effects of this limitation the parallel efficiency of an MPI application drops sharply once a second MPI process executes on the second processor of a dual processor motherboard. This is observed in Figure 1 for execution of an MPI application on an 8 node dual processor Linux cluster.
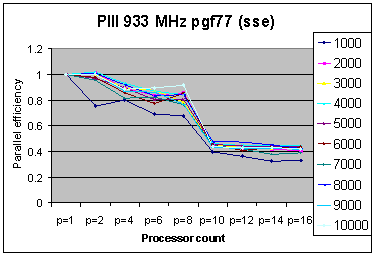
Fig.1 Performance of the Stommel Ocean Model in a Fortran MPI version for ten problem sizes. Note the sharp decline in parallel efficiency when more than 8 MPI processes are used on an 8 node dual processor cluster.
When 8 (or less ) MPI processes are used scalability (and efficiency) are excellent because only one MPI process executes on each node. However, when more than 8 MPI processes execute on this 8 node dual processor configuration, more than two MPI processes will reside on a node, and parallel efficiency declines sharply. A similar result is observed for a hybrid MPI and OpenMP version of the same code on the same cluster with 8 MPI processes and two OpenMP threads per node. These phenomena are due to multiple processes sharing the fixed memory bandwidth on multiprocessor motherboards. This problem is acute on the dual Pentium 3 configuration and, while somewhat ameliorated for the dual Pentium 4 Xeon, still persists. Therefore the STREAM benchmark has been applied here in an effort to obtain quantitative measures for the memory bandwidth limits on commodity platforms.
2.0 CHOICE OF HARDWARE AND OPERATING SYSTEM
Results for the memory bandwidth in MB/second are compared for benchmarks compiled using four different Fortran compilers with the Linux™ operating system. For this report benchmarks were executed in serial mode on a dual processor Intel™ Pentium III (256KB L2 cache, Supermicro 370DL3 motherboard) and a dual processor Pentium 4 Xeon 3.06GHz (1MB L3 cache, Supermicro X5DPA-TGM motherboard). These architectures offer Streaming Single-Instruction-Multiple-Data Extensions (with version 2, SSE2, for the Xeon). This enables vectorization of loops operating on multiple elements in a data set with a single operation. Where compilers specifically enable SSE/SSE2 it has been tested. However, it was found that use of SSE/SSE2 and prefetch compiler options, while used here, gave negligible performance enhancement over and above the standard optimizations. While the STREAM benchmark is designed to avoid compiler optimization differences, these were observed, and are reported. For these reasons results are presented both without and with compiler optimizations.
3.0 CHOICE OF COMPILERS
The choice of compilers for Linux™ IA-32 platforms now includes several vendor-supported products. The importance of this category is that vendor products have technical support and undergo continuous development with ports to new architectures as they arrive in the marketplace. The four compilers chosen in this survey are described separately in the following sections and compiler switches used in the benchmarks are also discussed. However, it is noted here that while all compilers offer a switch to target the Pentium 4, only three (Intel, Lahey, and Portland) offer a specific SSE/SSE2 option (see also notes below).
3.1 Absoft
Absoft f77 and f90/f95 are the Fortran compilers included in the Absoft Pro Fortran™ 8.0 package for Linux™ offered by the Absoft Corporation (http://www.absoft.com). The f90/f95 version has a Cray front-end and resulted from a five-year collaboration with Cray Research. With this compiler use of the –O3 compiler switch enables automatic architecture detection and selection of the Pentium 3 or 4 instruction set.
3.2 Intel
The Intel Fortran Compiler version 8.0 targets both Intel IA-32 and IA-64 (Itanium) architectures, but only the former has been used in this project so far. Details on the compiler features are available at HiPERiSM Consulting, LLC’s URL. Code for target architectures is generated with either the –tpp6 (Pentium 3) or –tpp7 (Pentium 4) switch.
3.3 Lahey
The Lahey/Fujitsu Fortran 95 compiler (hereafter Lahey) for Linux™ is available from Lahey Computer Systems, Inc., (http://www.lahey.com). The Express version 5.6 for Microsoft Windows 2000™ was used on the P3 and P4 because it was available from another project for the same hardware. With this compiler use of the –tpp compiler switch enables automatic architecture detection for the P3 only. However, release 7.1 (for Windows) and 6.2 (for Linux) support compiler switches –tp4 and –sse2 to target the Pentium 4 Xeon and the SSE2 instruction set. The 6.2 release was also used for the STREAM benchmark for this report but showed negligible differences from results reported here for version 5.6 on the P4.
3.4 Portland
The pgf90™ fortran compiler (Linux™ distribution) from the Portland Group, (http://www.pgroup.com) was used in the CDK 4.0 release where it supports OpenMP, MPI and OpenMP+MPI parallel applications on HiPERiSM’s IA-32 Linux™ cluster. With this compiler use of the –fast compiler switch enables automatic architecture detection. Note that the CDK 5.1 release (not used here) may offer additional performance enhancement of the Pentium 4 Xeon processor.
4.0 CHOICE OF BENCHMARKS
4.1 Introduction
The STREAM (Sustainable Memory Bandwidth) benchmark is fully described (and obtainable from) http://www.cs.virginia.edu/stream. It was developed and is maintained by John D. McCalpin, and this URL contains detailed descriptions, technical papers, and numerous results. In what follows only some salient features are outlined.
4.2 The STREAM benchmark and timing
The STREAM benchmark consists of multiple repetitions of the four Kernels in Table 4.1 and the best results of typically ten trials are chosen. Only the memory bandwidth is reported here (in units of MB/second) and for the definition of how memory bandwidth is measured in STREAM visit the above URL.
|
Table 4.1 Compute kernels of the STREAM benchmark (referenced by number in what follows). |
||||
|
No. |
Name |
Kernel |
Bytes / iterate |
Flops / iterate |
|
1 |
COPY |
a(i)=b(i) |
16 |
0 |
|
2 |
SCALE |
a(i)=q*b(i) |
16 |
1 |
|
3 |
SUM |
a(i)=b(i)+c(i) |
24 |
1 |
|
4 |
TRIAD |
a(i)=b(i)+q*c(i) |
24 |
2 |
For this report the iteration range of the loop is chosen to range from 1 to 20x106 data points with unit stride as this should ensure the data range will exceed the cache capacity. Also, the version of STREAM used here is a variant of the original stream_d.f code. A portable timing routine was added to record time intervals computed with calls to the Fortran 90/95 system_clock routine as follows
function mysecond()
integer, parameter:: b8 = selected_real_kind(14)
real(b8) mysecond
integer count,count_rate,count_max
call system_clock(count,count_rate,count_max)
mysecond=real(count,b8)/real(count_rate,b8)
end function mysecond
Negligible differences resulted from use of this procedure when compared with the non-portable fortran timing routines delivered with STREAM.
The compiler commands and the corresponding choice of command line switches are shown in Table 4.2 where switches without (column 2) and with (column 3) optimizations are distinguished.
|
Table 4.2 Compiler command and switches for the STREAM benchmark on the P3 and P4 processors. |
||
|
Compiler and version
|
Compiler command and switches without optimization |
Compiler command and switches with optimization |
|
Absoft 8.0 (P3) and (P4) |
f95 –s –N113 –ffixed f95 –s –N113 –ffixed |
f95 –s –O3 –cpu:p6 –N113 –ffixed f95 –s –O3 –cpu:p7 –N113 -ffixed |
|
Intel 7.1 (P3)
Intel 8.0 (P4) |
ifc –tpp6 –O0 –b0 –unroll0 –r8 –FI ifort –tpp7 –O0 –b0 –unroll0 –r8 –FI |
ifc –tpp6 –xK –O3 –Ob2 –ipo –prefetch- -r8 –FI ifc –tpp7 –xW –O3 –Ob2 –ipo –prefetch- -r8 –FI |
|
Lahey 5.6 (P3 & P4) |
lf95 –O0 –tpp –dbl -fix |
lf95 –tpp –dbl -fix |
|
Portland 4.0 (P3 & P4) |
pgf90 –O0 –r8 |
pgf90 –fast –Mvect=sse –r8 |
The next section presents the results of the STREAM benchmark using the respective compilers without optimization and Section 6 presents results with optimization.
5.0 COMPARING BANDWIDTH RATES WITHOUT COMPILER OPTIMIZATION
5.1 STREAM results with no optimizations
This section reports results with four compilers for the STREAM benchmarks with no compiler optimizations with the compiler switches shown in the second column of Table 4.2. Tables 5.1 (Pentium 3) and 5.2 (Pentium 4) show the numerical values and Figures 2 and 3, show these memory rates as bar charts, for Pentium 3 and Pentium 4, respectively.
|
Table 5.1 Memory bandwidth (MB/second) for the STREAM benchmarks with four compilers on the Pentium III (933 MHz) without optimization. |
||||
|
Kernel |
Absoft |
Intel |
Lahey |
Portland |
|
Copy |
218.93 |
262.57 |
230.22 |
250.59 |
|
Scale |
218.14 |
248.83 |
230.22 |
244.65 |
|
Add |
379.34 |
373.07 |
357.41 |
349.09 |
|
Triad |
328.4 |
361.39 |
365.85 |
344.33 |
|
Table 5.2 Memory bandwidth (MB/second) for the STREAM benchmarks with four compilers on the Pentium 4 Xeon (3.06 GHz, 1MB L3 cache) without optimization. |
||||
|
N |
Absoft |
Intel |
Lahey |
Portland |
|
Copy |
1252.27 |
1289.8 |
1077.44 |
1300.81 |
|
Scale |
1252.32 |
1314.17 |
1138.79 |
1316.87 |
|
Add |
1616.75 |
1651.76 |
1230.76 |
1655.17 |
|
Triad |
1649.41 |
1650.05 |
1230.76 |
1666.67 |
Kernels 3 and 4 show the higher values for both P3 and P4 cases because each has two memory loads and one store compared to one of each for the first two kernels. What is more interesting is the sharp increase in memory bandwidth for the P4 compared to the P3. For a more precise comparison of the memory bandwidth scaling from P3 to P4 architectures Figure 4 shows the ratio of the rates for each compiler on all four kernels. Typically scaling is in the range 3.4 (Lahey for kernel 4) to 5.7 (Absoft for kernel 1). The only anomaly is the low value with the Lahey compiler for kernels 3 and 4. Clearly, different compilers can produce different memory performance on the same code.
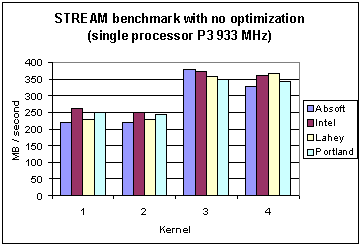
Fig. 2 Memory bandwidth of four different compilers for the STREAM benchmarks (without optimization) on the Pentium 3.
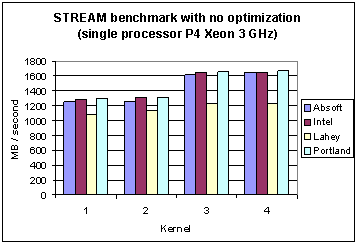
Fig. 3 Memory bandwidth of four different compilers for the STREAM benchmarks (without optimization) on the Pentium 4 Xeon.
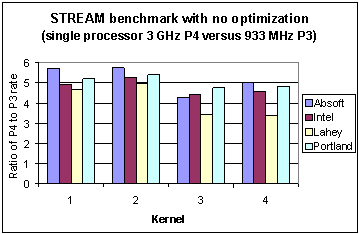
Fig. 4 Ratio of memory bandwidth of four different compilers on the Pentium 4 Xeon versus the Pentium 3 for the STREAM benchmark (without optimization).
5.2 STREAM statistics for no optimizations
Figures 5 and 6 show the basic statistics and some dispersion in values is evident with different compilers for each kernel. However, the standard deviation is seen to be small for all four kernels in the P3 case but is larger for the P4 case due to the outlier values of the Lahey compiler for kernels 3 and 4. Mean values scale by a factor of 3.4 (or better) when comparing Figures 5 and 6. This raises the expectation that memory bandwidth is, in general, significantly improved on the newer architecture irrespective of fluctuations with individual compilers.
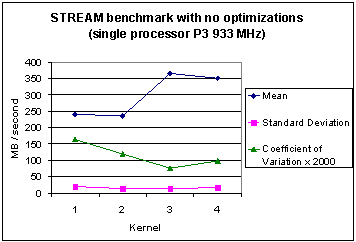
Fig. 5 Memory bandwidth statistics for four different compilers with the STREAM benchmark (without optimization) on the Pentium 3.
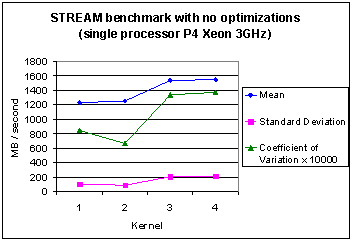
Fig. 6 Memory bandwidth statistics for four different compilers with the STREAM benchmark (without optimization) on the Pentium 4 Xeon.
6.0 COMPARING BANDWIDTH RATES WITH COMPILER OPTIMIZATION
6.1 STREAM results with optimizations
This section reports results with four compilers for the STREAM benchmarks with compiler optimizations using the compiler switches shown in the third column of Table 4.2. Tables 6.1 (Pentium 3) and 6.2 (Pentium 4) show the numerical values and Figures 7 and 8, show these memory rates as bar charts, for Pentium 3 and Pentium 4, respectively.
|
Table 6.1 Memory bandwidth (MB/second) for the STREAM benchmarks with four compilers on the Pentium III (933 MHz) with optimization. |
||||
|
Kernel |
Absoft |
Intel |
Lahey |
Portland |
|
Copy |
389.42 |
409.05 |
394.09 |
409.21 |
|
Scale |
259.96 |
401.81 |
402.01 |
399.5 |
|
Add |
394.07 |
496.69 |
503.67 |
493.32 |
|
Triad |
353.29 |
494.39 |
503.67 |
492.31 |
|
Table 6.2 Memory bandwidth (MB/second) for the STREAM benchmarks with four compilers on the Pentium 4 Xeon (3.06 GHz, 1MB L3 cache) with optimization. |
||||
|
N |
Absoft |
Intel |
Lahey |
Portland |
|
Copy |
1356.58 |
2677.82 |
1138.79 |
1322.31 |
|
Scale |
1351.96 |
2675.59 |
1207.55 |
1327.8 |
|
Add |
1660.76 |
2843.6 |
1227.62 |
1678.32 |
|
Triad |
1662.69 |
2802.1 |
1230.77 |
1684.21 |
A comparison of the effects of including compiler optimization show, in Figure 7, that all kernels have much higher memory bandwidth for the P3 (Table 6.1 versus 5.1). In this case the laggard is the Absoft compiler. With this exception, all compilers, with optimization enabled, again show a higher bandwidth for kernels 3 and 4. For the P4 the situation is quite different as shown in Figure 8. Comparing P4 and P3 (Table 6.2 versus 5.2), only the Intel compiler shows an impressive performance gain with an improvement of 1.8 on average. However, note that this is a compiler upgrade from version 7.1 on the P3 to 8.0 on the P4. Also, in the case of the P4, the Lahey compiler delivers noticeably lower bandwidth for kernels 3 and 4. More details on this comparison are given in Section 7.
Figure 9 shows the ratio of the P4 bandwidth when divided by the corresponding P3 rate, when compiler optimizations are enabled on both processors. This should be compared with Figure 4 for the no optimization case. Whereas all compilers gained from enabling optimization on the P3, the Absoft and Intel compilers show significant gains from enabling optimization on the P4. Typically scaling of memory bandwidth is in the range 2.4 (Lahey for kernels 3 and 4) to 6.7 (Intel for kernel 2). However, the dispersion in results of different compilers when optimization is enabled is wider than was the case without optimization (compare Figures 4 and 9). Clearly, the way in which hardware resources are allocated on the P4 Xeon differs widely in this group of compilers.
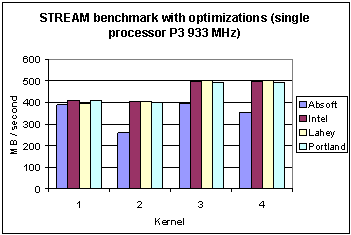
Fig. 7 Memory bandwidth of four different compilers for the STREAM benchmarks (with optimization) on the Pentium 3.
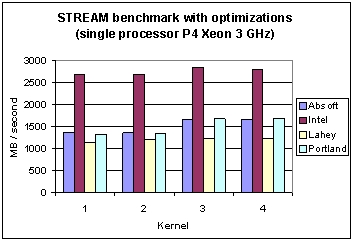
Fig. 8 Memory bandwidth of four different compilers for the STREAM benchmarks (with optimization) on the Pentium 4 Xeon.
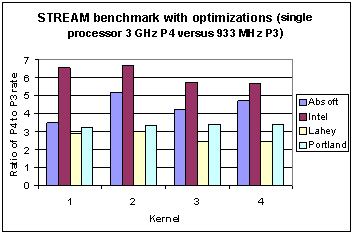
Fig. 9 Ratio of memory bandwidth of four different compilers on the Pentium 3 versus the Pentium 4 Xeon for the STREAM benchmark (with optimization).
6.2 STREAM statistics for optimizations
Figures 10 and 11 show the basic statistics and this shows some dispersion in values between different compilers for each kernel. However, the standard deviation is seen to be small for all four kernels in the P3 case but is larger for the P4 case due to the dispersion of values between the Intel and Lahey compiler for all kernels. Mean values scale by a factor of 4 when comparing Figures 10 and 11. This supports the expectation mentioned in the previous section that memory bandwidth is, in general, significantly improved on the newer architecture.
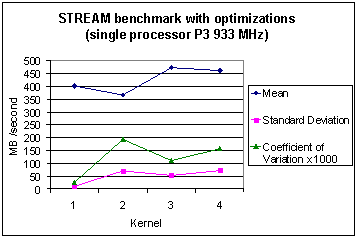
Fig. 10 Memory bandwidth statistics for four different compilers with the STREAM benchmark (with optimization) on the Pentium 3.
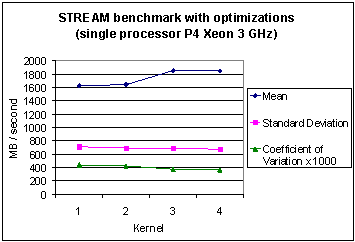
Fig. 11 Memory bandwidth statistics for four different compilers with the STREAM benchmark (with optimization) on the Pentium 4 Xeon.
7.0 COMPARING BANDWIDTH RATES WITHOUT AND WITH COMPILER OPTIMIZATION
For a direct comparison of the effects of including optimization switches (i.e. column 3 versus column 2 choices in Table 4.2) Figures 12 and 13 are presented. For the P3 in Figure 12, with the exception of the Absoft compiler for kernels 2-4, there is a gain in bandwidth by a factor in the range 1.3 to 1.8. Whereas for the P4 results shown in Figure 13 only the Intel compiler shows any significant gain in bandwidth when optimization is included.
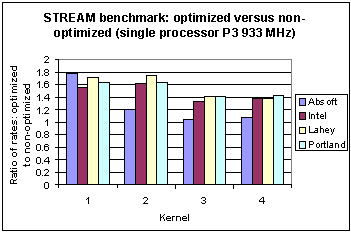
Fig. 12 Ratio of memory bandwidth of four different compilers on the Pentium 3 for results without and with compiler optimization for the STREAM benchmark.
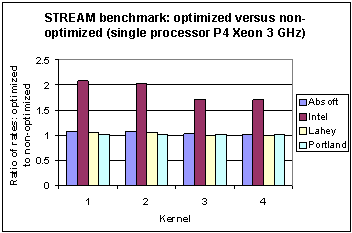
Fig. 13 Ratio of memory bandwidth of four different compilers on the Pentium 4 Xeon for results without and with compiler optimization for the STREAM benchmark.
8.0 CONCLUSIONS
This report presented performance results of four fortran compilers in the IA-32 environment for the STREAM memory bandwidth metric. The measurements were performed without and with compiler optimizations on Intel Pentium 3 and Pentium 4 Xeon processors used in serial mode on dual processor motherboards.
Some basic conclusions, when no optimizations are allowed, were:
· For the P3 and P4 all four compilers showed similar results on all four kernels (with the exception of one compiler on the P4).
· Comparison of P4 to P3 results showed individual rates enhanced by factors in the range 3.4 to 5.7, with mean values scaling up by a factor of 3.4.
When optimizations are allowed, some general observations were:
· For the P3 all four compilers showed similar results on all four kernels (with the exception of one compiler).
· Comparison of P4 to P3 results showed individual rates enhanced by factors in the range 2.4 to 6.6, with mean values scaling up by a factor of 4.
In general it may be concluded that code executed in serial mode on commodity dual processor motherboards can deliver a significant improvement in bandwidth on the P4 Xeon architecture when compared to the P3. For the P4 the Intel compiler delivered an exceptionally large memory bandwidth when optimization was enabled and this result suggests that MPI applications with one process per P4 dual node should experience the best memory performance.
To address the memory bandwidth issues for parallel code (as raised in the introduction of this report), the analysis must also include multi-process measurements on dual processor motherboards. The next report in this series applies the STREAM benchmark in the parallel (OpenMP) version to study how memory bandwidth scales with increasing thread count.
![]()
![]()
HiPERiSM Consulting, LLC, (919) 484-9803 (Voice)
(919) 806-2813 (Facsimile)

