HiPERiSM - High Performance Algorism Consulting
HCTR-2010-2: CMAQ Performance 2
CMAQ SERIAL AND MPI RESULTS
George Delic
HiPERiSM Consulting, LLC.
4.0 SERIAL AND MPI RESULTS
The section numbering continues from the previous report.
4.1 Intel™ compiler on three platforms
Runtime results for CMAQ 4.6.1 with the three solver versions is shown in Table 4.1 for three generations of Intel platforms with the highest optimization level (ifc4) for the Intel™ compiler.
Table 4.1. Wall clock times in hours for solvers in the serial version of CMAQ 4.6.1 for the Intel™ compiler with the fastest optimization (compiler group ifc4).
|
CMAQ Solver |
Time in hours by platform for Intel™ compiler group ifc4 |
||
|
Platform |
Itanium2™ ifc4 |
QC-1 ifc4 |
QC-2 ifc4 |
|
EBI-EPA |
46.4 |
16.2 |
12.6 |
|
ROS3-EPA |
54.2 |
25.7 |
17.3 |
|
GEAR-EPA |
81.8 |
37.1 |
29.7 |
All three solver versions of CMAQ have gained from the evolution of commodity computer architectures with an average speed-up versus the Itanium2™ of 2.4 (QC-1) and 3.2 (QC-2). However, the speed-up of CMAQ on QC-2 versus QC-1 is in the range 1.3 – 1.5 which is only half of the potential speed-up possible between two generations of quad-core processor technology.
4.2 Intel™ versus Portland™ compilers
Typical runtime results for the standard U.S. EPA distribution of CMAQ 4.6.1 are shown in Tables 4.2 and 4.3, for Intel™ and Portland™ compilers, respectively. In both cases the “*” indicates dedicated runs and all others are for concurrent execution. Table 4.4 show the ratios of times in corresponding cells of the preceding two tables.
Table 4.2. Wall clock times in hours for three solvers in the serial version of CMAQ 4.6.1 on the QC-1 platform for the Intel™ compiler switch groups ifc1 to ifc4.
|
CMAQ Solver |
Time in hours by compiler group |
|||
|
ifc1* |
ifc2 |
ifc3* |
ifc4* |
|
|
EBI-EPA |
74.4 |
16.3 |
20.5 |
16.2 |
|
ROS3-EPA |
147.4 |
25.8 |
30.0 |
25.7 |
|
GEAR-EPA |
183.7 |
37.1 |
41.4 |
37.1 |
The speed-up over the Itanium2™ platform with the Intel™ compiler is in the range 2.1 to 2.9 on the QC-1 platform, depending on the solver and compiler group used.
Table 4.3. Wall clock times in hours for three solvers in the serial version of CMAQ 4.6.1 on the QC-1 platform for the Portland compiler switch groups pgf1 to pgf4.
|
CMAQ Solver |
Time in hours by compiler group |
|||
|
pgf1 |
pgf2 |
pgf3* |
pgf4 |
|
|
EBI-EPA |
38.3 |
19.1 |
19.7 |
18.3 |
|
ROS3-EPA |
75.8 |
28.5 |
28.5 |
27.5 |
|
GEAR-EPA |
120.0 |
43.8 |
43.5 |
42.7 |
In the QC-1 case the difference in times for the ifc4 and pgf4 cases is due in part to the fact that the pgf4 runs were concurrent (overlapping) and this may expand wall clock time by the order of 10%.
Table 4.4. Ratios of wall clock times for three solvers in the serial version of CMAQ 4.6.1 on the QC-1 platform. The ratios are for Intel™ (ifc) versus Portland (pgf) compilers for each compiler switch group.
|
CMAQ Solver |
Ratios for wall clock time on the QC-1 platform and compiler group |
|||
|
ifc1 / pgf1 |
ifc2 / pgf2 |
ifc3 / pgf3 |
ifc4 / pgf4 |
|
|
EBI-EPA |
1.94 |
0.85 |
1.04 |
0.88 |
|
ROS3-EPA |
1.94 |
0.91 |
1.05 |
0.93 |
|
GEAR-EPA |
1.53 |
0.85 |
0.95 |
0.87 |
Note that, from Table 4.2, the increase in runtime for use of the Intel™ compiler group ifc3 versus ifc4 is in the range 10% to 27%, whereas for the Portland compiler the corresponding increase is in the range 2% to 8% (Table 4.3). As a result the comparative times for use of groups ifc3 and pgf3 in the respective compilers shrinks to the order of 5%. The use of the ifc3 and pgf3 compiler groups is recommended for reasons of improved precision in concentration values for some species.
4.3 MPI results
The preceding tables showed results for the standard U.S. EPA distribution with no parallel execution enabled. This section presents MPI results for EBI and Rosenbrock (ROS3) chemistry solver versions of CMAQ 4.6.1. Table 4.5 summarizes the CMAQ 4.6.1 runtimes (in hours) with the Portland compiler in an MPI implementation. Also shown there is the scaling with increasing MPI process count and it is notable that speedup departs significantly from linearity with more than 4 MPI processes.
Table 4.5. Wall clock times (in hours), parallel scaling, and parallel efficiency for two solvers in the MPI implementation of EPA’s standard release of CMAQ 4.6.1 on the HiPERiSM QC Cluster platform for the Portland compiler group pgf3.
|
Col x Row = NP |
Time in hours (EPA) |
MPI speedup versus NP=1 |
MPI parallel efficiency | |||
|
EBI |
ROS3 |
EBI |
ROS3 |
EBI |
ROS3 |
|
|
1 x 1 = 1 |
19.6 |
29.0 |
1.0 |
1.0 |
1.00 |
1.00 |
|
1 x 2 = 2 |
10.9 |
15.1 |
1.8 |
1.9 |
0.90 |
0.96 |
|
2 x 2 = 4 |
6.4 |
8.2 |
3.1 |
3.5 |
0.76 |
0.88 |
|
2 x 4 = 8 |
3.9 |
5.1 |
5.1 |
5.7 |
0.64 |
0.71 |
|
2 x 8 = 16 |
2.6 |
3.3 |
7.5 |
8.7 |
0.47 |
0.54 |
|
4 x 4 = 16 |
2.9 |
3.4 |
6.8 |
8.4 |
0.42 |
0.52 |
Corresponding to the previous table, Fig 4.1 summarizes the CMAQ 4.6.1 MPI parallel efficiency with increasing process count. It is clear that EBI and ROS3 solvers show a steep decline in MPI parallel efficiency when NP>4. The asymptote of parallel efficiency is of the order of 50% for 16 MPI processes where CPUs are idle for half of the wall clock time (on average).
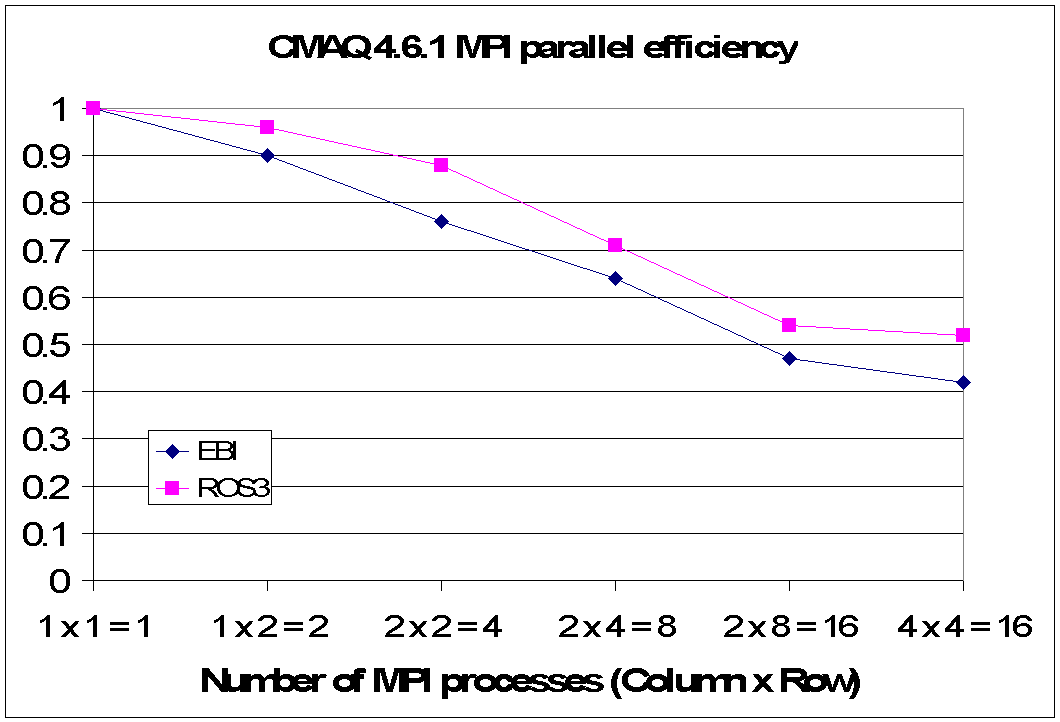
Fig. 4.1. MPI Parallel efficiency for CMAQ 4.6.1 EBI and ROS3 solvers.
ACKNOWLEDGEMENTS
Part of this work was performed by HiPERiSM Consulting, LLC, as subcontractor to Computer Sciences Corporation, under U.S. EPA SES3 Contract GS-35F-4381G BPA 0775, Task Order 1522
Follow the "Next" button to view the next report in this series.
![]()
![]()
HiPERiSM Consulting, LLC, (919) 484-9803 (Voice)
(919) 806-2813 (Facsimile)

