HiPERiSM - High Performance Algorism Consulting
HCTR-2011-3: Benchmarks with three compilers on Intel® processors (2010)
BENCHMARKS WITH THREE COMPILERS ON Intel® PROCESSORS (2010)
George Delic
HiPERiSM Consulting, LLC.
1.0 CHOICE OF BENCHMARK
1.1 The Stommel Ocean Model
HiPERiSM has used the Stommel Ocean Model (SOM) as a simple case study in training courses across various HPC platforms and it is useful as a test bed for new architectures. It has been described in a previous report (HCTR-2001-3) and for this benchmark the problem size sets the number of interior grid point at N=30,000 for a Cartesian grid of 30,000 x 30,000 with a total memory image in excess of 20 Gbytes. This domain is divided into horizontal slabs with each slab distributed to separate MPI processes. In the hybrid OpenMP+MPI version of SOM used here, each horizontal slab is further subdivided into thread-parallel chunks in an OpenMP work scheduling algorithm. The chunk size differs depending on the value of the product for the number of MPI processes times the number of OpenMP threads, but the parallel work scheduling algorithm remains the same.
1.2 Hardware test bed
The hardware platform for this benchmark exercise is the 2-processor (2P) Intel W5590 quad core node, as described in Table 1.1 of a preceding report (HCTR-2011-1). Of interest here is to compare the multi-core performance with CPUs on a single mother board sharing a bus architecture. For the same benchmark on an Advanced Micro Devices (AMD) platform see the preceding report HCTR-2011-2.
2.0 COMPILING THE BENCHMARK
To compile the hybrid OpenMP + MPI SOM model three compilers were used. These included Absoft (11.0), Intel (11.0) and Portland (10.6) compilers. All compilations used the highest level of optimizations available for this host with each compiler using double precision arithmetic. For all three compilers the MPICH mpirun command was used with the -all-local switch to contain executions on-node.
3.0 BENCHMARK RESULTS
3.1 Wall clock times
Wall clock times for the Absoft, Intel and Portland compilers are shown in Tables 3.1, 3.2, respectively. The three compilers offer differences in performance times and, in general, the best times are for the Portland compiler. Therefore Figs. 3.1 and 3.2 show the ratio of the wall clock times to the corresponding Portland results for the other two compilers.
Table 3.1 . Absoft and Intel compiler wall clock time in seconds with problem size N=30,000 in the SOM benchmark on the Intel quad core W5590 2P node. The tabular configuration is row-wise for OpenMP thread count and column-wise for MPI process count.
|
|
Table 3.2. Portland compiler wall clock time in seconds with problem size N=30,000 in the SOM benchmark on the Intel quad core W5590 2P node. The tabular configuration is row-wise for OpenMP thread count and column-wise for MPI process count.
|
Portland |
OMP |
|
|
|
|
|
MPI |
1 |
2 |
4 |
6 |
8 |
|
1 |
576.5 |
294.9 |
268.6 |
264.5 |
275.7 |
|
2 |
271.6 |
176 |
255.4 |
|
|
|
4 |
225.1 |
172.2 |
|
|
|
|
6 |
182.7 |
|
|
|
|
|
8 |
192.3 |
|
|
|
|
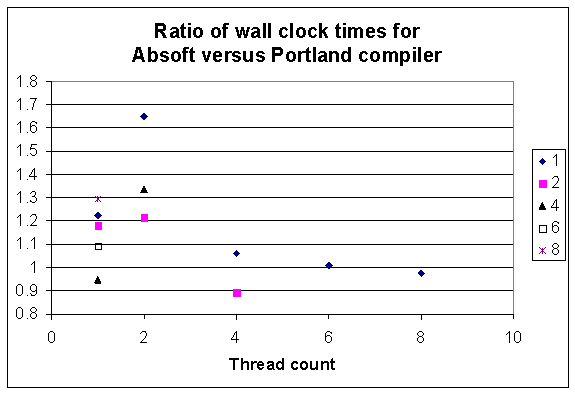
Fig 3.1. The ordinate shows the ratio of wall clock time of Absoft versus Portland compiler with problem size N=30,000 in the SOM benchmark on the Intel quad core W5590 2P node. The horizontal axis is the OpenMP thread count and the legend shows the number of MPI processes. The number of cores utilized is the product of the two values.
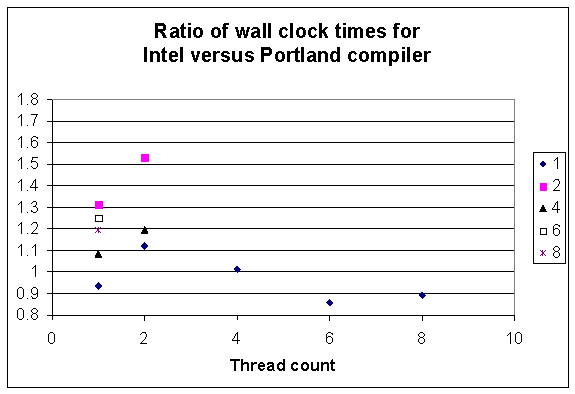
Fig 3.2. The ordinate shows the ratio of wall clock time of Intel versus Portland compiler with problem size N=30,000 in the SOM benchmark on the Intel quad core W5590 2P node. The horizontal axis is the OpenMP thread count and the legend shows the number of MPI processes. The number of cores utilized is the product of the two values.
3.2 Scaling with thread count
Scaling by OpenMP thread count, with a fixed number of MPI processes, for the Absoft, Intel and Portland compilers are shown in Tables 3.3 and 3.4, respectively. The three compilers offer reasonable scaling for 1 MPI process, but this declines for more than 1 MPI process.
Table 3.3. Absoft and Intel compiler scaling by OpenMP thread count for a fixed number of MPI processes with problem size N=30,000 in the SOM benchmark on the Intel quad core W5590 2P node. The tabular configuration is row-wise for OpenMP thread count and column-wise for MPI process count.
|
|
Table 3.4. Portland compiler scaling by OpenMP thread count for a fixed number of MPI processes with problem size N=30,000 in the SOM benchmark on the Intel quad core W5590 2P node. The tabular configuration is row-wise for OpenMP thread count and column-wise for MPI process count.
|
Portland |
OMP |
|
|
|
|
|
MPI |
1 |
2 |
4 |
6 |
8 |
|
1 |
1.00 |
1.95 |
2.15 |
2.18 |
2.09 |
|
2 |
1.00 |
1.54 |
1.06 |
|
|
|
4 |
1.00 |
1.31 |
|
|
|
|
6 |
1.00 |
|
|
|
|
|
8 |
1.00 |
|
|
|
|
3.3 Scaling with MPI process count
Scaling by MPI process count, with a fixed number of OpenMP threads, for the Absoft, Intel and Portland compilers are shown in Tables 3.5 - 3.6, respectively. The three compilers offer poor scaling when the number of threads is larger than 2, although this is difficult to judge.
Table 3.5 . Absoft and Intel compiler scaling by MPI process count for a fixed number of OpenMP threads with problem size N=30,000 in the SOM benchmark on the Intel quad core W5590 2P node. The tabular configuration is row-wise for OpenMP thread count and column-wise for MPI process count.
|
|
Table 3.6 . Portland compiler scaling by MPI process count for a fixed number of OpenMP threads with problem size N=30,000 in the SOM benchmark on the Intel quad core W5590 2P node. The tabular configuration is row-wise for OpenMP thread count and column-wise for MPI process count.
|
Portland |
OMP |
|
|
|
|
|
MPI |
1 |
2 |
4 |
6 |
8 |
|
1 |
1.00 |
1.00 |
1.00 |
1.00 |
1.00 |
|
2 |
2.12 |
1.68 |
1.05 |
|
|
|
4 |
2.56 |
1.71 |
|
|
|
|
6 |
3.16 |
|
|
|
|
|
8 |
3.00 |
|
|
|
|
3.4 Results for fixed chunk size and core count
The results above were for multiple combinations of MPI processes and OpenMP threads ranging from 1 to 8. This section shows results selected for combinations of MPI processes and OpenMP threads where the product of their respective numbers is exactly 8, for example, 2 MPI processes and 4 OpenMP threads, or 4 MPI processes and 2 OpenMP threads. The other reason for this selection is that the parallel chunk size per thread is constant for all such combinations, and this equalizes one variable affecting memory usage when comparing the three compilers. For this selection Fig. 3.3 shows the results of wall clock times extracted as the highlighted values along the diagonal from Tables 3.1,3.2, whereas Fig. 3.4 shows the corresponding ratios of these times to the Portland result.
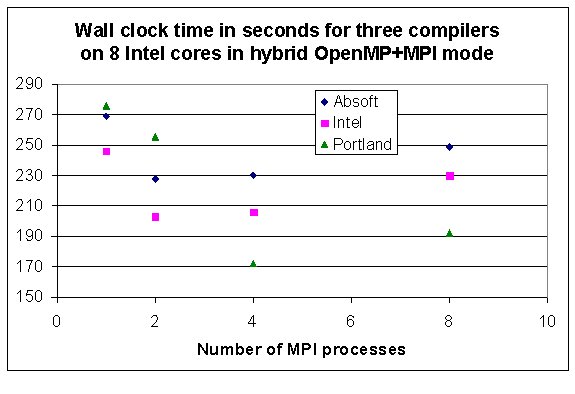
Fig. 3.3. Wall clock time of three compilers with problem size N=30,000 in the SOM benchmark on the Intel quad core W5590 2P node in OpenMP+MPI hybrid mode such that the product for the number of MPI processes and OpenMP threads is 8. The horizontal axis shows the number of MPI processes.
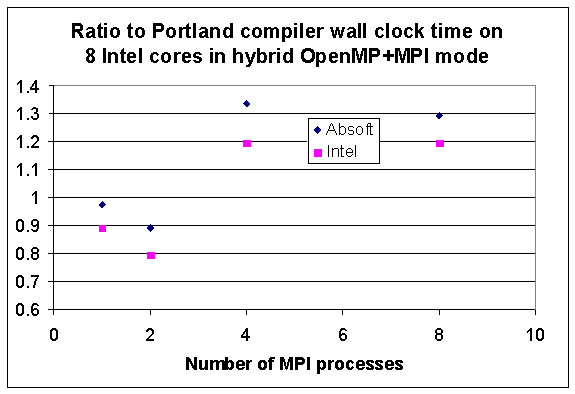
Fig 3.4. Ratio of wall clock time of Absoft and Intel compilers to the Portland result with problem size N=30,000 in the SOM benchmark on the Intel quad core W5590 2P node in OpenMP+MPI hybrid mode such that the product for the number of MPI processes and OpenMP threads is 8. The horizontal axis shows the number of MPI processes.
4.0 ANALYSIS OF RESULTS
Exploratory benchmarks comparing three compilers on a simple hybrid model with a regular data structure showed the smallest wall clock times for the Portland compiler over a broad parameter range of a parallel hybrid MPI+OpenMP SOM model. Relative to the corresponding Portland results, the variability in wall clock times was largest for the Absoft, compiler when the number of MPI processes was less than 8, whereas the variability of Absoft and Intel wall clock times was similar for more than 8. The greatest divergences occur at thread counts of 1,2,4 and 12, and for MPI process counts of 1 and 12. Possible causes are cache effects or thread/process data affinity issues. The latter relates to where data resides relative to the host core for each thread or process. While it is possible to schedule MPI processes to specific (numbered) cores with the mpiexec command in MPI2, no such effort was implemented here, and all scheduling was left to the runtime libraries of the respective compilers and the operating system.
For scaling with increasing MPI process, or OpenMP thread count, all three compilers showed acceptable results when these counts where less than, or equal to, 4. Outside this range scaling results were poor. This could be an artifact of insufficient arithmetic work inside the corresponding (smaller) parallel chunks since parallel granularity is more refined with increasing core count. This issue is more acute on the Intel node because of the reduced problem size.
5.0 COMPARING AMD AND INTEL PROCESSORS
It is of interest to compare performance of the Intel W5590 quad core processor node against the AMD 6176SE 12 core processor discussed in the preceding report (HCTR-2011-2). In the comparison one consideration is that the total memory available on the Intel quad core node is 24 GB (compared to the AMD node with 120 GB). While there is room for more memory on the Intel node, the limit of 24GB was chosen to maximize Bus speed (see footnote 2 in Table 1.1 of report HCTR-2011-1). For this reason, on the Intel platform, the the problem size is reduced to fit the memory available and therefore and the parallel chunk size is also smaller. Nevertheless the compiler options are unchanged and the total number of cores utilized is limited to 8. Fig. 5.1 shows the ratio of wall clock times for three compilers with the hybrid OpenMP+MPI model utilizing 8 cores on AMD and Intel nodes. There is a wide divergence at 4 MPI processes because of the large speed-up of the Absoft compiler on the Intel Nehalem node when compared to the AMD node. For the three compilers the average speed-up is 2.6 (Absoft), 2.3 (Intel), and 1.9 (Portland), respectively, in moving the application (under the same conditions) from the AMD node to the Intel node.
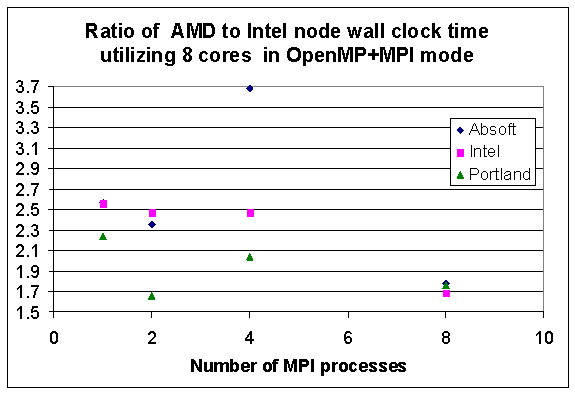
Fig 5.1. Ratio of wall clock time on the AMD 6176SE 12 core 4P node versus the Intel quad core W5590 2P platform for three compilers with problem size N=30,000 in the SOM benchmark. The hybrid OpenMP+MPI hybrid mode is chosen such that the product for the number of MPI processes and OpenMP threads is 8. The horizontal axis shows the number of MPI processes.
6.0 CONCLUSIONS
With 8 cores on the Intel node the scope of this benchmark exploration was considerably more limited compared to the flexibility of the AMD node of the preceding report. Nevertheless these exploratory benchmark measurements confirm the impressive results that are possible with the Intel Nehalem quad core processor architecture. Specifically, the Intel compiler at low MPI process counts of less than 4, is the leader in wall clock time, followed closely by the Absoft compiler. Above this range the Portland compiler leads. Scaling results saturate rapidly with increasing core count, suggesting the Intel Nehalem processor is very adept at dealing with higher computational intensity. Computational speedup of this Intel processor over the AMD CPU in the previous report is in the range 1.9 - 2.6. However, actual performance of commodity solutions in real-world applications will vary and results for specific Air Quality Models (AQM) are the subject of subsequent reports.
![]()
![]()
HiPERiSM Consulting, LLC, (919) 484-9803 (Voice)
(919) 806-2813 (Facsimile)

