HiPERiSM - High Performance Algorism Consulting
HCTR-2010-4: CMAQ Performance 4
CMAQ CPU versus GPGPU BENCHMARKS
George Delic
HiPERiSM Consulting, LLC.
7.0 OPPORTUNITIES FOR PERFORMANCE
The section numbering continues from the previous report.
7.1 Multi-thread CMAQ on a CPU
For ROS3-HC successful performance relies on enhanced vector loop capability in the Rosenbrock solver to take advantage of instruction level parallelism. As noted previously (Delic, 2009), all 43 candidate loops in the OpenMP version of CMAQ’s Rosenbrock solver do vectorize. All that remains is to make the best choice of vector length, NCMAX, and BLKSIZE, such that BLKSIZE/NCMAX has no remainder. The choice of values for the best BLKSIZE and NCMAX combination depends on the cache and memory architecture. Empirical studies (Delic, 2009) determined that, for host CPU architectures such as QC-1 and QC-2, NCMAX should be in a range 18 to 90 and BLKSIZE ≤ 480. Typically, values of vector loop length NCMAX > 90 and larger BLKSIZE choices increase the runtime on multi-core commodity processors.
7.2 Many-thread CMAQ on a GPGPU
A successful port to a GPGPU device requires either multilayered loop nests, or very long (single) loops to reap the benefits of the many threads such devices employ. This suggest that if the NCMAX “vector” length could be made very large there could be throughput benefits for a CMAQ parallel version adapted for such devices. If at the same time, the number (BLKSIZE) of cells in a block could be increased, then the number of such blocks passed to the solver would be reduced. Consequently, the number of calls to the CMAQ chemistry solver algorithm is fewer, and loops spanning the entire block would be off-loaded to the many-core device. This motivates the interest in exploring the port of the ROS3-HC thread-safe version of CMAQ to a GPGPU device.
7.3 Benchmark of CMAQ loop nests
As a sequel to the above proposal the vector length for loops over domain cells in the CMAQ 4.6.1 ROS3-HC version was set equal to the block size (NCMAX= BLKSIZE) with values of BLKSIZE incremented in a wide range. Table 7.1 shows the vector length increments chosen for this analysis on both the host CPU (X5450) and the GPGPU device (C1060). The domain size of 2,276,640 cells corresponds to the episodes described in Section 3 in report HCTR-2010-1.
Table 7.1. Range of vector lengths used in benchmarks on the host CPU and GPGPU device for a 279x240x34 domain size.
|
Number of blocks = number of calls to the solver |
Blocksize = vector length |
|
8894 |
256 |
|
4447 |
512 |
|
2224 |
1024 |
|
1112 |
2048 |
|
556 |
4096 |
|
278 |
8192 |
|
139 |
16384 |
|
70 |
32768 |
For timing benchmarks several loop nests from the CMAQ ROS3-HC thread parallel version were selected. Table 7.2 lists the loop names used below in figure legends. Details of the source code constructs are described in report HCTR-2010-5.
Table 7.2. Loop names for loop nest benchmarks.
|
CMAQ-ROS3 solver loops used in benchmarks |
||
|
Loop name |
Number of loop nests in parallel region |
Loop nest depth |
|
L478 |
1 |
2 |
|
L522-37 |
2 |
2 |
|
L1240 |
2 |
2 and 1 |
|
L1284 |
3 |
1, 2, and 1 |
The Portland 10.6 Fortran compiler was used with the pgf3 compiler group. For the host CPU the loops were compiled as single threaded loops. In the GPGPU case, the Portland Accelerator™ compiler generated kernels and data movement for the target device by recognition of accelerator directives that encapsulated loop nests in the benchmarks. In conducting these benchmarks no additional GPGPU optimizations were performed.
8.0 COMPARISON OF CPU AND GPGPU
For the benchmarks listed in Table 7.2 in the ROS3-HC version of CMAQ results of benchmarks are presented for two performance metrics as a function of increasing vector length:
- Ratio of times on the GPGPU device versus the host CPU.
- Ratio of time for GPGPU computation (kernel) versus time for moving data between host and GPGPU device (data).
The first metric indicates a gain for the GPGPU over the CPU performance when the value is less than unity. The second metric is an indicator of the level of computational intensity (flops per memory operation) in each benchmark. Results of these metrics for the range of vector length in Table 7.1 are shown in Figs. 8.1 and Fig. 8.2, respectively.
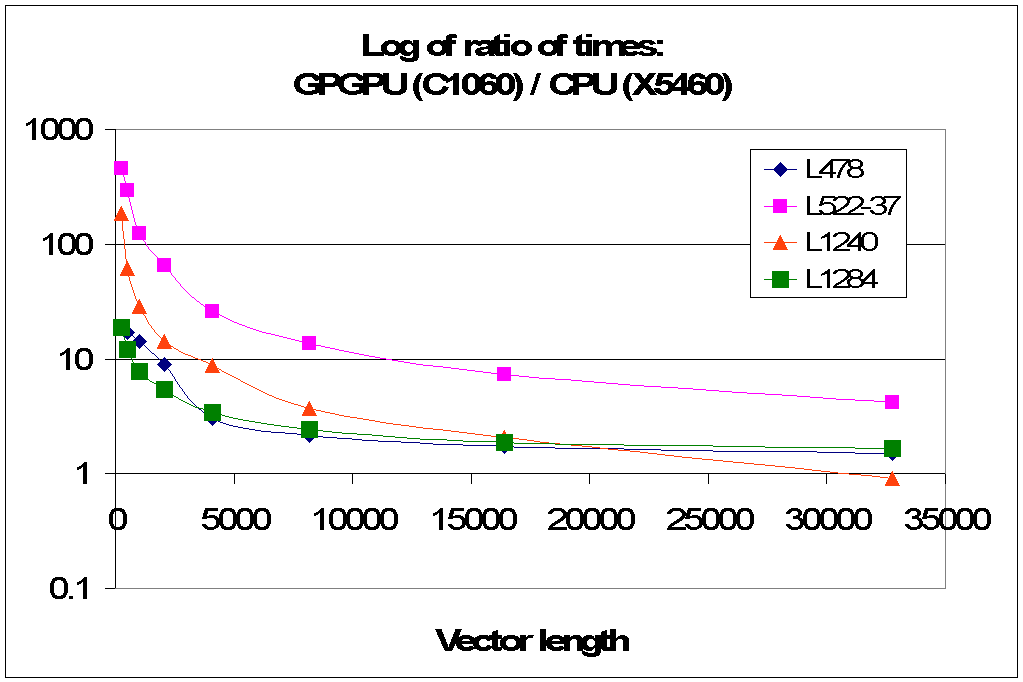
Fig 8.1: Ratio of time on the GPGPU device versus the host CPU for each of the four CMAQ benchmarks in Table 7.2.
Fig.8.1 shows that, with smaller values of the vector length, the times on the host CPU are typically orders of magnitude faster than the GPGPU device. However, as vector length increases, there is a rapid gain for GPGPU performance with the L1240 benchmark outperforming the host CPU time for the longest vector length.
However, one of the penalties for using the attached GPGPU device is the cost of moving data between the host and the device. For three of the benchmarks, Fig.8.2 shows the ratio of computation time to data movement time when the GPGPU is utilized. For the largest vector lengths this ratio is ≤ 1 suggesting that the cost of data movement dominates the kernel computation time.
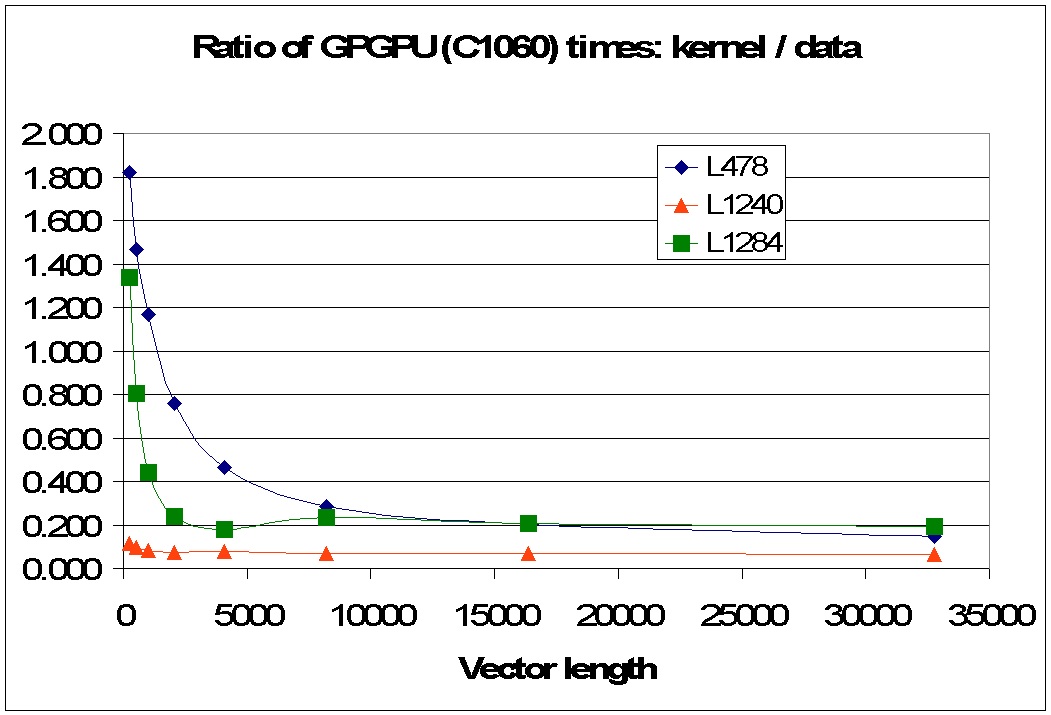
Fig 8.2: Ratio of time spent in kernels on the GPGPU device versus the time required to move data between the host CPU and the GPGPU device for three CMAQ benchmarks in Table 7.2.
9.0 CONCLUSIONS
This series of reports has described a successful port to recent multi-core CPUs of a parallel hybrid (OpenMP and MPI) version of CMAQ for the Rosenbrock solver. Exploratory benchmarks with selected loops on a many-core GPGPU device suggest that opportunities exist for CMAQ on such devices, but further work is needed to improve performance. Also, further opportunities remain for thread parallelism in other parts of the CMAQ model outside of the chemistry solver.
Follow the "Next" button to view the next report in this series.
![]()
![]()
HiPERiSM Consulting, LLC, (919) 484-9803 (Voice)
(919) 806-2813 (Facsimile)

