HiPERiSM - High Performance Algorism Consulting
2011-1: The many-core revolution has arrived - are you ready?
All trademarks mentioned are the property of the owners and opinions expressed here are not necessarily shared by them. HiPERiSM Consulting, LLC, will not be liable for incidental or consequential damages in connection with, or arising out of, the furnishing, performance, or use of the products or source code discussed in these reports.


The recent changes in the commodity computing industry have moved us from the familiar to the unfamiliar. The next revolution in commodity hardware has arrived and we take the opportunity to make some comments on this and a few other topics of current interest to us. HiPERiSM's newsletters are far apart because in the interim we are busy participating in each revolution in commodity computing. We remain focused on our prime services: training, software sales and consulting for the High Performance Computing community working with clusters of commodity compute nodes. We are motivated to share the learning experience with what is currently available for many-core and multi-core solutions in our applications to air quality modeling (AQM) development.
- George Delic, Ph.D.
TABLE OF CONTENTS
2.0 High Performance Computing Hardware Trends and Cost Benefit
3.0 High Performance Computing Software Trends
4.0 Performance issues on Commodity processors
5.0 Consequences for source code construction
This discussion will focus on developments in hardware, software and programming practices for commodity cluster users. Since our 2006 newsletter the predicted trend has been realized with a growth in the number of cores per CPU for commodity solutions from Intel [INTEL] and Advanced Micro Devices (AMD) [AMD]. For High Performance Computing (HPC) applications, the major recent development is the emergence of General Purpose Graphical Processing Units (GPGPU) as computing devices with many cores. Also the acceptance of 64-bit commodity hardware (x86_64) has been rapid in recent years to the extent that this must now be viewed as the default environment for operating systems, compilers, and applications. For scientific computing this is relevant because of much larger memory address range and the native support for double precision arithmetic. In the following sections we revisit some of the topics covered over five years ago in the previous newsletter with a similar template. To make these more relevant we recite our own experience of real-world code in use by the Air Quality Modeling (AQM) community. AQM models have followed the path of industry trends and migrated from proprietary HPC platforms to commodity clusters over the last decade. In our experience AQM models have much to gain from commodity technology trends but are largely ill-prepared to take advantage of them. This is because AQMs contain obsolete legacy code that will not enable a modern compiler's use of new hardware instruction sets to implement inherent task or data parallelism. Such models needs code transformations to enable scalable parallel performance. For details on this subject see HiPERiSM's presentations at the CMAS conferences for 2003-2010 [CMAS].
2.0 High Performance Computing Hardware Trends and Cost Benefit
Two important recent developments in commodity hardware have important consequences for software development with commodity clusters. The first of these is the growth in the number cores per CPU in processor hardware. Examples include the quad core Intel Pentium Xeon Nehalem� [INTEL], and the 12 core Opteron� from AMD [AMD]. This a change from the time of our previous 2006 newsletter when, at best, dual core CPU's with separate GPR's, functional units, and cache hardware were available.
The second important development has been the rapid assimilation of many core GPGPU devices available as separate servers or add-on PCI cards [NVIDIA]. Both of these changes have had repercussions for the cost benefit calculation of commodity processors and some of these factors are summarized in Table 1. This table is based on hardware installed at HiPERiSM since our last newsletter.
| Table 1: Cost and number of cores for recent many/multi core hardware | |||
|
Platform |
Unit cost |
Number of cores |
Cost per core |
|
Intel Nehalem� (W5590) |
$1,690 |
4 |
$423 |
|
AMD Opteron� (6176SE) |
$1,371 |
12 |
$114 |
|
Nvidia C1060 |
$1,300 |
240 |
$5.4 |
|
Nvidia C2070 |
$3,600 |
448 |
$8.0 |
Power consumption and feature density considerations dictate that commodity processors are limited in how many multiple cores may be supported in a single CPU. This is one reason why there has been much interest in GPGPU technologies. The analysis of power consumption per core in Table 2 is compelling evidence of GPGPU technology attractiveness. Heat output is the other side of power consumption, and even at 3.7 times less power consumption per core (compared to the Nehalem�) the AMD Opteron� CPU in a 4P configuration is still a large source of heat. This requires enhanced plans for facility cooling capacity. In this respect, the order of magnitude reduction in per-core power consumption for the GPGPU solution is a strong argument for adoption. Yet another argument for GPGPU adoption is the peak theoretical floating point performance shown in the last column of Table 2 where single precision (SP) and double precision (DP) Gflop/s are listed. Although the Gflop/s per core is larger on the CPU processors, the GPGPU technology leads by an order of magnitude due to the much larger number of cores. As a side note, comparison of the theoretical peak Gflop/s for the two CPUs in Table 2 would seem to suggest that 12 cores of the AMD CPU are equivalent to 4 cores of an Intel CPU. However, in practice when an Intel Nehalem� 2P node (8 cores) is compared with a 4P Opteron� platform (48 cores) a CMAQ workload takes less time on the latter node, once the core count is more than doubled compared to the former (see the details in Section 3.2 of HCTR-2011-4).
| Table 2: Power and performance | |||
|
Platform |
Power consumption (Watts) |
Performance: theoretical peak Gflops (SP/DP) |
|
|
Average |
Per core |
||
|
Intel Nehalem� (W5590) |
130 |
32.5 |
106.6 / 53.3 |
|
AMD Opteron� (6176SE) |
105 |
8.75 |
110.4 / 55.2 |
|
Nvidia C1060 |
160 |
0.67 |
933 / 77 |
|
Nvidia C2070 |
238 |
0.53 |
1030 / 515 |
The growth in the number of cores per CPU has been accompanied by a remarkable growth in on-CPU and on-node bandwidth. The first technical report issued this year includes detailed measurements of on-node bandwidth for recent hardware and compares it with the legacy NumaLink� interconnect of the SGI Altix� (HCTR-2011-1). Fig. 1 shows effective bandwidth scaling with Message Passing Interface (MPI) process count on four separate cluster nodes. The results are so impressive that they suggest applications should reside as much as possible on the node. This development in memory bandwidth is coincident with the availability of large memory capacity on 64-bit commodity hardware. As an example, HiPERiSM's AMD node has 120GB of global memory, and this is only half of the available capacity on the motherboard. Taken together these new features of commodity compute nodes support software development for large memory models within a Shared Memory Parallel (SMP) programming paradigm such as OpenMP.
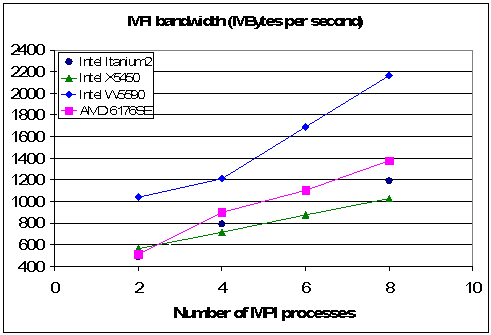
Fig. 1 Effective bandwidth on four nodes with 8 CPUs (or cores) on each (from HCTR-2011-1).
3.0 High Performance Computing Software Trends
As in the past, the two dominant parallel programming paradigms are MPI and OpenMP so our emphasis has been to develop and test hybrid parallelism. However, recent developments in parallel programming environments for GPGPU devices includes directive style support in the PGI Accelerator compiler [PGI], and proposals for portable standards such as Open Computing Language [OpenCL], or Compute Unified Device Architecture [CUDA].
As we observed in the 2006 newsletter, the richness and choice of features in compiler technology for these commodity hardware developments has also grown enormously. The key vendor compilers that are tested regularly at HiPERiSM are those from Intel [INTEL], STMicroelectronics (The Portland Group) [PGI], and Absoft [ABSOFT]. In the near term we also plan to test other compilers that come at no charge. Furthermore, OpenMP, as a shared memory parallel (SMP) paradigm, is now supported by all of the compilers currently available. When combined with MPI libraries that are also available either from vendors [INTEL], or at no charge [MPI], the scope for hybrid parallel applications is flourishing.
The MPI standard [MPI] continues in common use for the commodity cluster computing market. However, with the advent of multi-core CPUs implementation of hybrid MPI and SMP levels of parallelism could be beneficial for performance scaling. Hybrid parallel computing models have been explored in the past, but their utility with dual processor commodity environments was limited. At HiPERiSM we have successfully developed such a hybrid parallel model of the CMAQ model by adding thread-level parallelism to the existing MPI implementation. In real-world code we continue to seek opportunities for hybrid parallelism and, where it is successfully realized, measure parallel scalability as functions of the number of MPI processes and OpenMP threads. Two recent reports measure performance on Intel and AMD nodes for a hybrid OpenMP + MPI model (HCTR2011-2, HCTR2011-3). Beyond MPI, HiPERiSM is exploring the opportunities for porting of CMAQ to GPGPU many core devices (see 2010 Annual CMAS meeting [CMAS]).
4.0 Performance Issues on Commodity Processors
The emphasis going forward will be on parallel performance (Macroperformance) versus the serial performance (Microperformance) of applications of interest (for a definition of these terms see the discussion in the 2006 newsletter). In this respect new releases of compilers are explored in their capability for generating both instruction and loop level parallelism. This has been a focus of attention by inspection of compiler messages for key compute intensive code segments. Compilers have grown more sophisticated in their analysis of optimization opportunities and careful timing benchmarks of compute intensive kernels is essential. These activities have been extended to compute kernels with GPGPU devices as targets and results will be the subject of future reports.
At HiPERiSM efforts are concentrated on core execution efficiency. Firstly by ensuring candidate loops use SSE vector instructions and secondly load balance between parallel thread team members. Continued evolution of the extended SSE instruction set makes the first concentration area always current. For load balance issues extensive studies have been undertaken with variable vector length and parallel chunk sizes for CMAQ. An important empirical observation has been that since the introduction of the Intel 64EMT� there have been important enhancements in tolerance for wide variations of these parameters. For AQM's results of these investigations will be the subject of future reports in the technical reports pages.
The benchmarks currently under study are listed in Table 3 and are a small subset that we have used over the years because of their special characteristics, or because customers have requested a performance analysis for the implementation shown.
|
Table 3: A subset of HiPERiSM Benchmarks |
||
|
Mnemonic |
Features |
Implementation |
| SOM | Stommel Ocean Model is a floating point algorithm with excellent vector structure in a double nested loop for a Jacobi sweep with a 5-point FD stencil | Hybrid MPI+OpenMP |
| AERMOD | An AQM with voluminous memory traffic and control transfer instructions | OpenMP (in progress) |
| CMAQ | An AQM with voluminous memory traffic | Hybrid MPI+OpenMP |
The technical reports pages give more details of these algorithms and benchmarks results will continue to be added as work on them progresses. Currently efforts are focused on the two AQM's listed above because they share the common characteristic of showing very little vector instruction issue, and consequently, negligible capability to take advantage of SSE instruction sets on commodity processors. In the case of CMAQ, HiPERiSM has added OpenMP threading and enhanced SSE instruction use for all thread team regions. Work on AERMOD continues, but this remains a challenge because of the predominantly legacy scalar code constructs in the U.S. EPA release [AERMOD].
It has been our practice to examine all available compilers for Linux systems, but we have tended to confine attention to the commercially supported ones. Even amongst these the main interest is in the compilers in used by the AQM community and these include those from Absoft [ABSOFT], the Portland Group [PGI], and Intel [INTEL]. We report what we find since our experience in scientific research leads us to believe that showing the objective facts is the best path to finding answers to questions such as:
- What is the measured performance?
- Why does one benchmark give different performance compared to another?
- Why are there numerical differences with different compilers and optimization switches?
We have found that all compilers have undergone very significant maturation with the arrival of the multi core hardware technology. Since new (major) compiler releases often come with compiler bugs, it is important to apply at least two different compilers to the same benchmark in mission critical projects to validate numerical accuracy. One example in our experience was numerical differences in CMAQ produced by the Intel 11.0 compiler for the highest optimization levels for some chemical species. When "safe math" options were enabled there was a two orders of magnitude reduction in these numerical differences (at the cost of a longer execution time). Such occurrences are to be expected in rapidly evolving compiler technology for commodity platforms, and hence the caution in validation of model results. New technical reports in 2011 compare the vendor supported compilers from Intel, Portland Group, and Absoft (see Technical Reports).
4.4 Issues with commodity solutions
The fundamental issue with commodity hardware solutions is the performance cost of accessing memory. The challenge of optimizing the balance between memory operations and arithmetic operations continues to be crucial because commodity architectures compromise on memory bandwidth and latency to reduce costs. Applications such as AQM's with a voluminous rate of total memory instructions need to be examined carefully. However, as mentioned above, the more recent many-core CPUs introduce enhanced memory bandwidth and latency (see Fig. 1). As a result wall-clock times have been reduced for some AQM's. Nevertheless, considerable work remains to be done on the model codes to remove the parallel code inhibitors that remain.
The emergence of GPGPU hardware brings with it a new requirement for modifying compute intensive code segments. The modifications must transform algorithms into a form suitable for exploitation of the numerous cores available on platforms such at the Nvidia Tesla� cards [NVIDIA] listed in Table 1. This problem is alleviated by developments in the programming environments [CUDA, PGI] that move the art of parallel programming to a higher level. The directive style approach of the PGI Accelerator programming model [PGI] is reminiscent of vector and thread-level directive styles, but with added levels of complexity. This interface does enhance self-paced learning in the GPGPU environment. However, not all codes (or algorithms) are suitable for the GPGPU programming paradigm. The additional consideration of memory copy time between host CPU and GPGPU device must be judiciously balanced against computational speed if overall wall clock time is to be reduced.
An additional consideration is the lack of an industry-wide adoption of a standard for the GPGPU programming environment. While discussions are in progress, and proposals have been made (see Section 3.2 above), portability of code across architectures is problematic at this time.
5.0 Consequences for source code construction
The challenge remains with the programmer to develop code for optimal parallel performance that is also structured to present compilers with ample opportunity to engage host CPU cores and and overlap with operations on GPGPU devices. This means applying the usual practices for parallel code construction:
- Simplifying the calling tree within potential parallel code blocks
- Partitioning code blocks for distribution to host team threads
- Removing parallel inhibitors from code blocks
- Introducing nested loop code blocks as potential GPGPU compute kernels
- Implementing portable parallel constructs
There is nothing new in these basic practices for constructing parallel code. However, they require some re-thinking of the code to match the capabilities of multi core and many core architectures in moving from the familiar to the unfamiliar in commodity computing developments.
There appears to be a distinct hardware trend in future CPU designs that will blend traditional host x86_64 architectures with GPGPU capability on the same CPU form factor. Future and current developments in hardware and software offer an opportunity for orders of magnitude increases in performance. However, they also require refinement in programming practices. Compilers remain limited in their ability to transform code and the developer is key in this process. Current parallel programming paradigms such as MPI, may loose their dominance as new ones emerge. Model developers must continue to engage in the transition of existing models to many core parallel architectures and evaluate the software options with respect to suitability to this task based on the criteria of level-of-effort, usability, and scalability. Such a plan should have these focal points:
Level-of-effort: Choice of level where the programmer best engages.
- Usability: The resulting code is portable to future parallel paradigms.
- Scability: Hybrid parallel mode scales efficiently.
For large applications hybrid parallel models that use OpenMP and MPI with clustered SMP nodes will be with us for some time but the GPGPU programming paradigms may overturn this dominance in the not too distant future.
A discussion of these issues will continue in future HiPERiSM Consulting, LLC, Newsletters and Technical Reports.
| ABSOFT | http://www.absoft.com |
| AERMOD |
EPA-SCRAM: U.S. EPA, Technology Transfer Network, Support Center for Regulatory Air Models http://www.epa.gov/scram001/. |
| AMD | http://www.amd.com |
| CMAQ | http://www.cmaq-model.org |
| CMAS | http://www.cmascenter.org |
| CUDA | http://www.nvidia.com/object/cuda_home_new.html |
| INTEL | http://www.intel.com |
| MPI | The Message Passing Interface (MPI) standard, http://www.mcs.anl.gov/mpi/index.html. |
| NVIDIA | http://www.nvidia.org |
| OpenCL | www.khronos.org/opencl |
| OPENMP | http://www.openmp.org |
| PGI | http://www.pgroup.com |
HiPERiSM Consulting, LLC, (919) 484-9803 (Voice)
(919) 806-2813 (Facsimile)
![]()
![]()