HiPERiSM - High Performance Algorism Consulting
HCTR-2001-6: Compiler Performance 7


1.0 The Stommel Ocean Model: 2-D MPI decomposition + OpenMP Hybrid
1.1 Serial and MPI+OpenMP hybrid code
This is a comparison of parallel MPI+OpenMP hybrid performance with SUN Fortran compilers on the SUN E10000™ platform for a floating-point intensive application. The application is the Stommel Ocean Model (SOM77) and the Fortran 77 source code was developed by Jay Jayakumar (serial version) and Luke Lonnergan (MPI version) at the NAVO site, Stennis Space Center, MS. It is available at http://www.navo.hpc.mil/pet/Video/Courses/MPI_Finite. The algorithm is identical to the Fortran 90 version discussed in report HCTR-2001-2 but the Fortran 77 version allows for more flexibility in the domain decomposition for MPI. The OpenMP hybrid version was developed by HiPERiSM Consulting, LLC, as part of case studies for the training courses.
This
is a 2-dimensional domain decomposition in both the x and y direction with horizontal and
vertical square slabs of the domain passed to different MPI processes (one square
sub-domain per process). In the MPI version all parameters must be broadcast by process
with rank 0 to all processes before computation begins. Otherwise the code is identical to
the serial version excepting that each MPI process operates on its own square of the
domain. At the beginning of each iteration the processes synchronize boundary values by
exchanging adjacent ghost arrays (parallel to either the x or y direction) with the
nearest neighbor processes whenever square sides are adjacent (subroutine EXCHANGE). The
exterior boundaries of the outermost squares do not exchange rows since they correspond to
domain boundaries. The hybrid version placed OpenMP parallel regions for loop nests such
as the compute kernel that performs a Jacobi iteration sweep over a two-dimensional
finite difference grid (where the number of iterations is set to 100). In this hybrid
model there are two levels of parallel granularity with MPI at the coarser grain and
OpenMP at the finer grain. All MPI procedures are called by the master thread and none are
called from any OpenMP parallel region. This is to ensure a "safe" coding
practice that makes no assumptions about the thread safety of the MPI library used. For
this reason the call to MPI_ALLREDUCE has been moved out of the OpenMP parallel region.
There is an implied barrier at the end of the OpenMP parallel region (all threads on all
OpenMP nodes must have completed computation before the MPI reduction operation). Here two
reduction operations are performed: one for OpenMP threads on each node and another for
MPI processes between nodes. The problem sizes chosen were N=1000 for a 1000 x 1000 and
N=2000 for a 2000 x 2000 finite difference grid. Static scheduling was used for the OpenMP
work distribution with a scheduling parameter isched chosen to vary with problem size and MPI processs and OpenMP thread
count.
2.1 MPI+OpenMP parallel performance for N=1000
For problem size N=1000 this section shows parallel performance for the Stommel Ocean Model (SOM77) in a 2-D MPI domain decomposition with the SUN Fortran 77 compiler using a hybrid MPI+OpenMP parallel model. <>
Table 2.1a shows results for the MPI+OpenMP version executed on the SUN E10000 for 1, 2Ç 2 and 4Ç 4 MPI processes and 1, 2, and 4 threads. The speed up shown there is relative to the case of one MPI process and one OpenMP thread. This is a 64 processor node and the workload impacted the last example.
| Table 2.1a: Performance summary for hybrid MPI+OpenMP Stommel Ocean Model (SOM77) in a 2-D MPI decomposition (problem size 1000) | ||||||
Wall clock time (sec) |
Speed up |
|||||
1 MPI process |
4 MPI processes |
16 MPI processes |
1 MPI process |
4 MPI processes |
16 MPI processes |
|
1 thread |
6.13 |
0.88 |
0.25 |
1.00 |
7.00 |
24.5 |
2 threads |
3.13 |
1.00 |
0.50 |
1.96 |
6.13 |
12.3 |
4 threads |
1.25 |
0.50 |
18.8 |
4.90 |
12.3 |
0.33 |
Table 2.1b shows how the value of the OpenMP scheduling parameter isched changes and the corresponding OpenMP speed up for each value of the number of MPI processes.
| Table 2.1b: OpenMP scheduling parameter isched (speed up) for hybrid MPI+OpenMP Stommel Ocean Model (SOM77) in a 2-D MPI decomposition (problem size 1000) | |||
1 MPI process |
4 MPI processes |
16 MPI processes |
|
1 thread |
500 (1.00) |
250 (1.00) |
125 (1.00) |
2 threads |
250 (1.96) |
125 (0.88) |
62 (0.50) |
4 threads |
125 (4.90) |
62 (1.75) |
31 (0.013) |
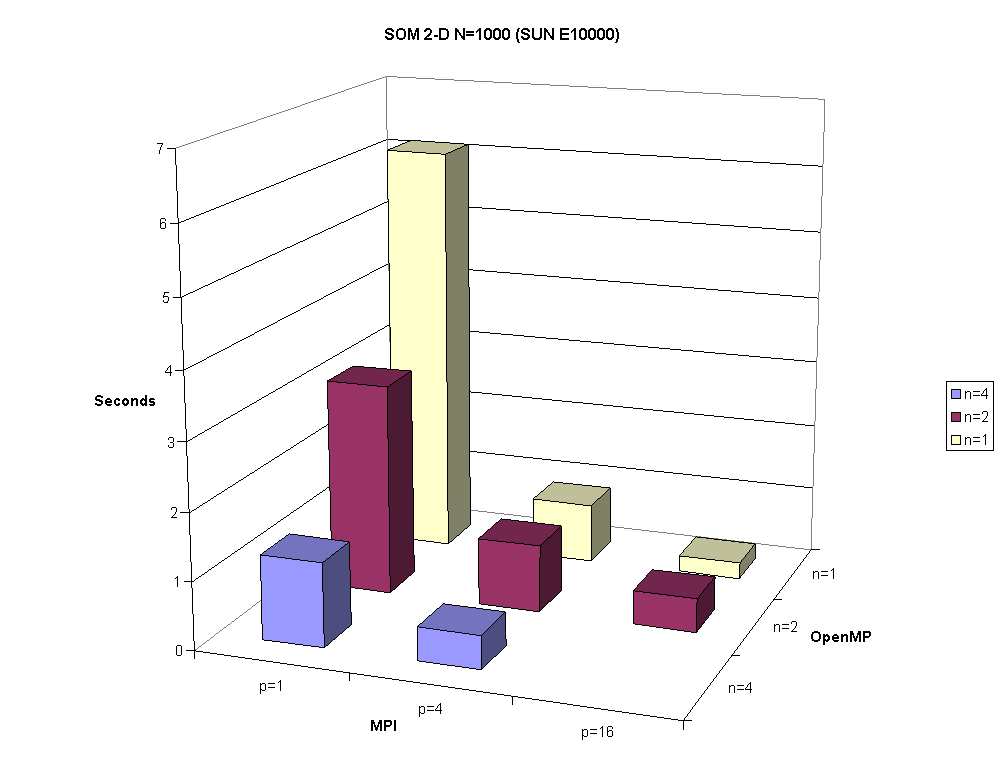
Fig. 2.1. Time to solution in seconds for SOM 2-D when N=1000 in a hybrid MPI+OpenMP model on the SUN E10000 for 1, 2
Ç2 and 4Ç4 MPI processes and 1, 2, and 4 threads.
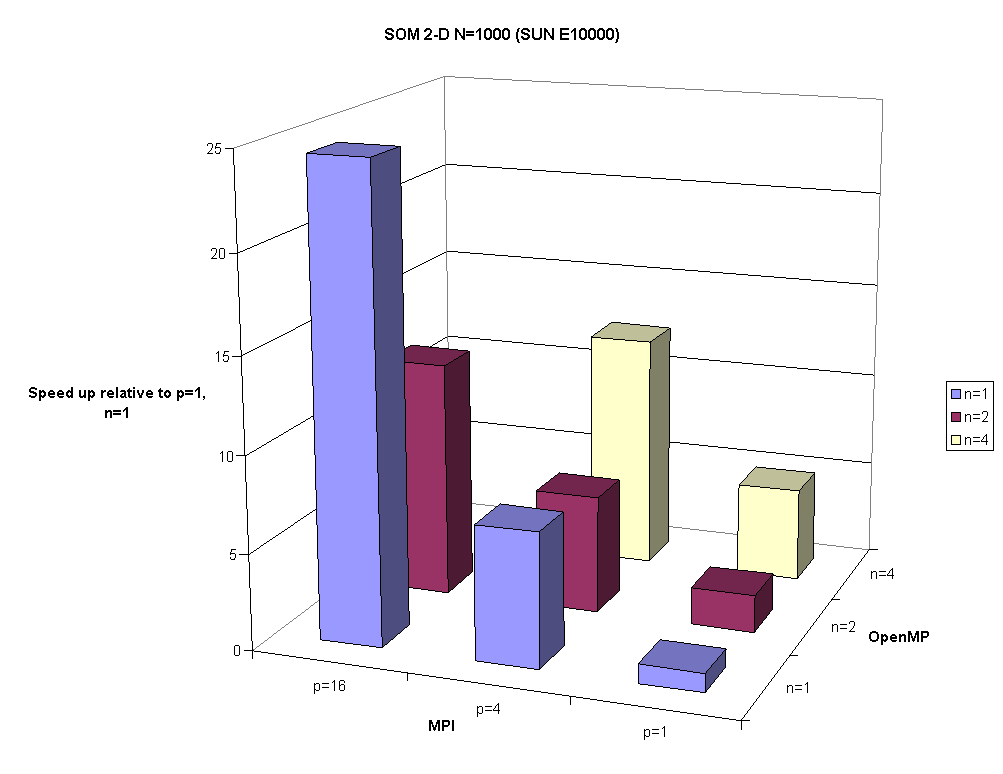
Fig. 2.2. Speed up for SOM 2-D when N=1000 in a hybrid MPI+OpenMP model on the SUN E10000 for 1, 2Ç2, and 4Ç4 MPI processes and 1, 2, and 4 threads.
3.1 MPI+OpenMP parallel performance for N=1000
For problem size N=2000 this section shows parallel performance for the Stommel Ocean Model (SOM77) in a 2-D MPI domain decomposition with the SUN Fortran 77 compiler using a hybrid MPI+OpenMP parallel model.
Table 3.1a shows results for the MPI+OpenMP version executed on the SUN E10000 for 1, 2Ç 2 and 4Ç 4 MPI processes and 1, 2, and 4 threads. The speed up shown there is relative to the case of one MPI process and one OpenMP thread. This is a 64 processor node and the workload impacted the last example.
| Table 3.1a: Performance summary for hybrid MPI+OpenMP Stommel Ocean Model (SOM77) in a 2-D MPI decomposition (problem size 2000) | ||||||
Wall clock time (sec) |
Speed up |
|||||
1 MPI process |
4 MPI processes |
16 MPI processes |
1 MPI process |
4 MPI processes |
16 MPI processes |
|
1 thread |
44.88 |
7.5 |
0.75 |
1.00 |
5.98 |
59.8 |
2 threads |
22.62 |
3.5 |
1.5 |
1.98 |
12.8 |
29.9 |
4 threads |
12.00 |
2.0 |
5.25 |
3.74 |
22.4 |
8.55 |
Table 3.1b shows how the value of the OpenMP scheduling parameter isched changes and the corresponding OpenMP speed up for each value of the number of MPI processes.
| Table 3.1b: OpenMP scheduling parameter isched (speed up) for hybrid MPI+OpenMP Stommel Ocean Model (SOM77) in a 2-D MPI decomposition (problem size 2000) | |||
1 MPI process |
4 MPI processes |
16 MPI processes |
|
1 thread |
1000 (1.00) |
500 (1.00) |
250 (1.00) |
2 threads |
500 (1.98) |
250 (2.14) |
125 (0.50) |
4 threads |
250 (3.74) |
125 (3.75) |
62 (0.14) |
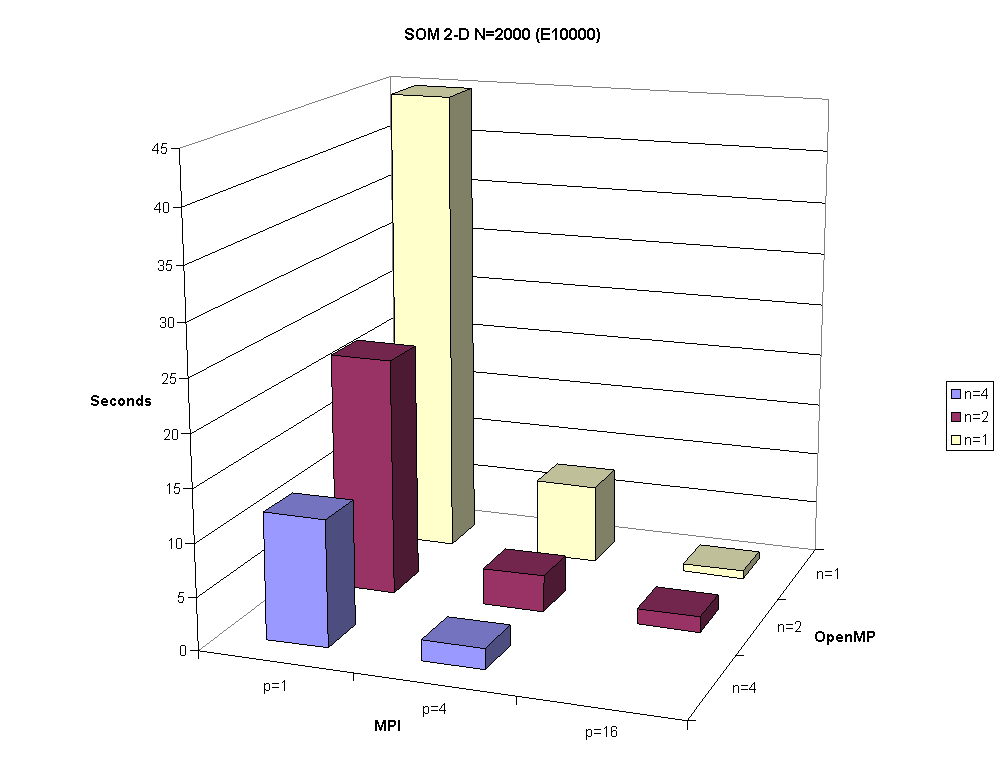
Fig. 3.1. Time to solution in seconds for SOM 2-D when N=2000 in a hybrid MPI+OpenMP model on the SUN E10000 for 1, 2Ç2 and 4Ç4 MPI processes and 1, 2, and 4 threads.
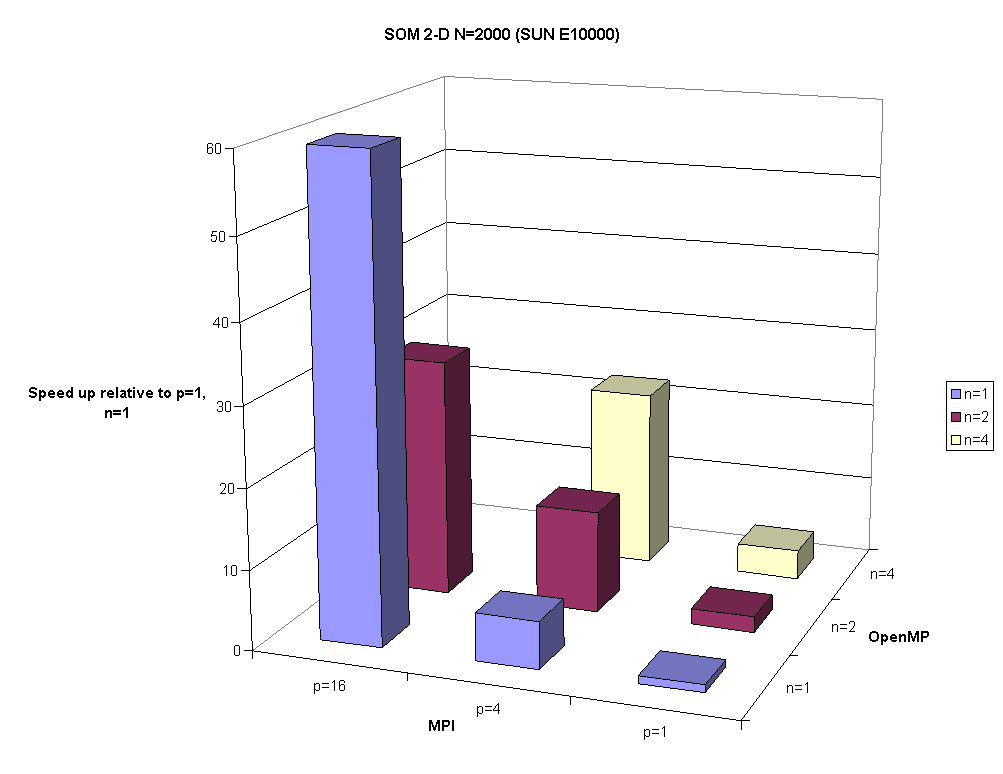
Fig. 3.2. Speed up for SOM 2-D when N=2000 in a hybrid MPI+OpenMP model on the SUN E10000 for 1, 2
Ç2, and 4Ç4 MPI processes and 1, 2, and 4 threads.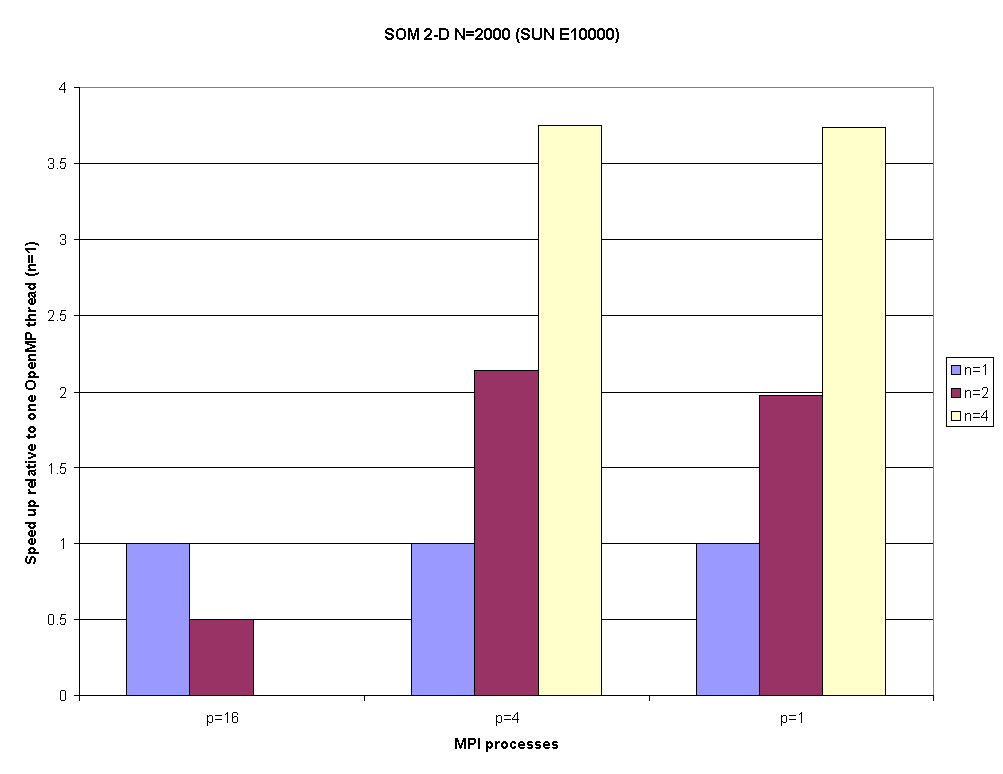
Fig. 3.3. Speed up relative to one thread for SOM 2-D when N=2000 in a hybrid MPI+OpenMP model on the SUN E10000 for 4Ç4, 2Ç2, and 1 MPI processes, respectively, and 1, 2, and 4 threads..
![]()
![]()
HiPERiSM Consulting, LLC, (919) 484-9803 (Voice)
(919) 806-2813 (Facsimile)